 On May 4, NVIDIA announced its latest accessible supercomputing initiative, Tesla Preconfigured Clusters. I spoke with Sumit Gupta, senior product manager for the Tesla group at NVIDIA, to get the skinny on this latest project.
On May 4, NVIDIA announced its latest accessible supercomputing initiative, Tesla Preconfigured Clusters. I spoke with Sumit Gupta, senior product manager for the Tesla group at NVIDIA, to get the skinny on this latest project.
Back during SC08 in Austin last year, NVIDIA unveiled their Personal Supercomputer. NVIDIA wasn’t selling these themselves, but the company prescribed standards that hardware vendors could use to earn the right to display the Personal Supercomputer badge on their product. To get that badge a system must meet a set of hardware standards (minimum quad core CPU, at least 4 GB of system memory per GPU, and so on), and the system must pass a set of tests that are evaluated by NVIDIA, along with some other legal requirements.
The tagline for the Personal Supercomputer project is “One Researcher, One Supercomputer,” and this fits for a system that gives you up to about 4 TFLOPS of peak from four C1060 cards (or 3 C1060 and a Quadro) and plugs into a standard wall outlet. Word from some of those selling this system is that sales have been mostly in the academic space and a little slower than expected, possibly due to the initially high ($10k+) price point. Prices have started to come down, however, and that might help sales. You can buy these today from vendors like Dell, Colfax, AMAX, Microway, and Penguin (for a partial list see NVIDIA’s PS product page).
NVIDIA’s new Tesla project is the Preconfigured Cluster, which the company calls “Accessible Supercomputing,” and it follows the model of the Personal Supercomputer project. Again NVIDIA isn’t selling these themselves, but is working with hardware partners who will sell these systems to ensure that they meet minimum specifications and requirements to earn the badge. The clusters are built from NVIDIA’s rack-mountable S1070 nodes coupled with with CPU servers. Throw in some head nodes and your choice of InfiniBand or GigE, and you are ready to go. The clusters come ready to turn on, pre-loaded with MPI, CUDA development tools, and cluster management software.
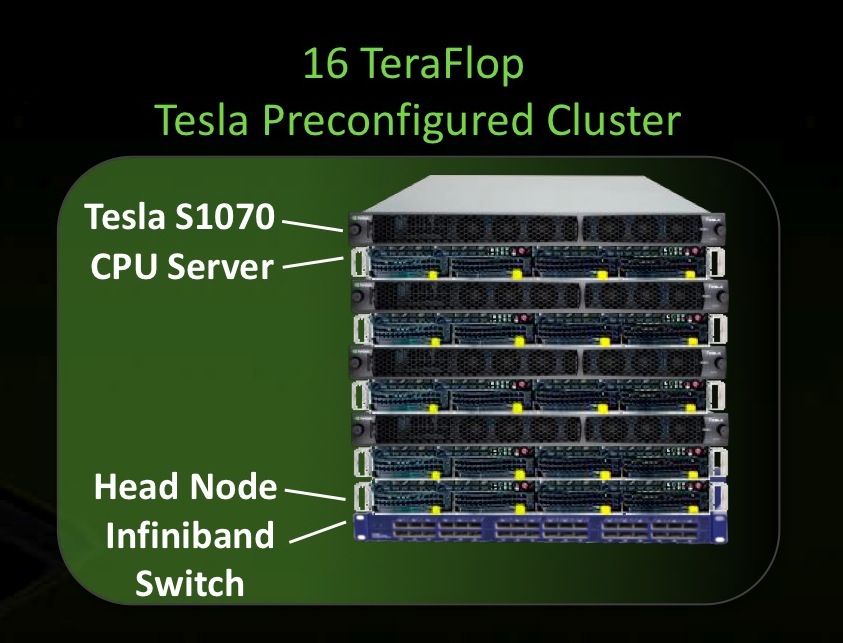 The S1070s are PCIe-connected to the CPU servers, and the CPU servers are connected via the network. The physical model is analogous to the Personal Supercomputer systems, only with rackmount boxes instead of cards inside deskside boxes. The programming model is MPI for coarse-grained workload distribution among the CPU servers, and then use CUDA to move that work onto the GPUs for computation. The same model works on the Personal Supercomputer systems, so users can develop on a personal platform and move to the larger workgroup platform without having to retune their codes. Today clusters are Linux systems, but support for Windows Server is expected in the near future.
The S1070s are PCIe-connected to the CPU servers, and the CPU servers are connected via the network. The physical model is analogous to the Personal Supercomputer systems, only with rackmount boxes instead of cards inside deskside boxes. The programming model is MPI for coarse-grained workload distribution among the CPU servers, and then use CUDA to move that work onto the GPUs for computation. The same model works on the Personal Supercomputer systems, so users can develop on a personal platform and move to the larger workgroup platform without having to retune their codes. Today clusters are Linux systems, but support for Windows Server is expected in the near future.
Sumit Gupta says the ratio of CPUs to GPUs isn’t specified; there is a minimum of 1 core to 1 GPU (there are four GPU cards in each S1070, so this means a quadcore socket could minimally host a single S1070), but users may want higher ratios depending upon their applications. A small system would put about 16 TFLOPS in the GPUs and run about $50,000 US.
NVIDIA’s briefing package for the clusters has two examples of customers replacing traditional CPU-only clusters with CPU/GPU clusters and achieving dramatic power and cost savings. The BNP Paribas (finance) study showed a $250,000 500 core cluster (37.5 kW) replaced with a 2 S1070 Tesla cluster at a cost of $24,000 and using only 2.8 kW. A study with oil and gas company Hess showed an $8M 2000-socket system (1.2Mw) being replaced by a 32 S1070 cluster for $400,000 and using only 45 kW in 31x less space. If you are running a CUDA-enabled application, or have access to the source code (you’ll need that to take advantage of the GPUs), you can clearly get significant performance gains for certain applications.
NVIDIA is launching with a raft of vendors signed up to offer the clusters, including Cray (who will slot the servers in their CX1 platform), Penguin, Appro, Colfax, James River, and others.
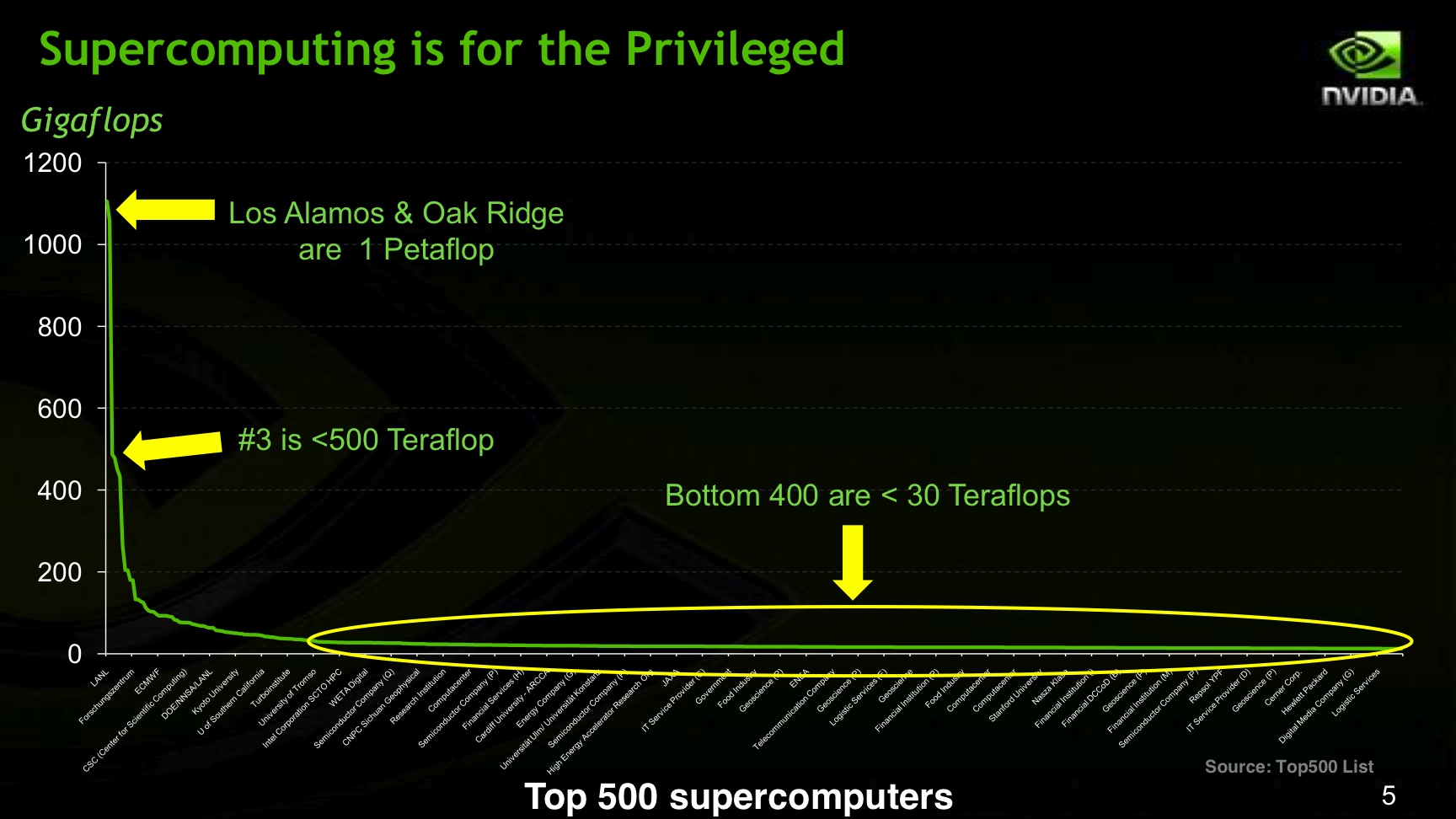 During our conversation, Gupta emphasized all of the Tesla efforts as projects that “make computing available to more people,” and showed me an arresting slide of the distribution of FLOPS in the Top500 list (image at right, click for a larger version). When I asked him how he measures success toward this goal, he told me an interesting story about all the 18 year-old kids who are wanting to get their code posted to NVIDIA’s developer site, CUDA Zone. 18 year-olds in HPC? That is a pretty powerful leading indicator.
During our conversation, Gupta emphasized all of the Tesla efforts as projects that “make computing available to more people,” and showed me an arresting slide of the distribution of FLOPS in the Top500 list (image at right, click for a larger version). When I asked him how he measures success toward this goal, he told me an interesting story about all the 18 year-old kids who are wanting to get their code posted to NVIDIA’s developer site, CUDA Zone. 18 year-olds in HPC? That is a pretty powerful leading indicator.


Alright nVidia, now get moving on CULAPACK. 🙂
– Brian, who just got his Tesla C1060 today
NVIDIA should correct their table by replacing the y-axis label with teraflops instead of gigaflops.
Spoke to an early CUDA service and porting shop who worked with NVidia. They had started talking about contracting a port, but then NVidia backed out. Their interpretation is that NVidia wanted the community to do the port.
Nothing seems to be emerging in the community or commercial side.