By Timothy Prickett Morgan • Get more from this author
The mystery surrounding the architecture of the future “Titan” supercomputer to be installed at Oak Ridge National Laboratories and funded by the US Department of Energy is over.
Oak Ridge, which is the US nuke lab most associated with open (rather than classified and often military) science, has been working with Cray and Nvidia on future hybrid CPU-GPU designs for several years and is Cray’s keystone HPC customer. So it is no surprise that the Titan supercomputer will marry Cray’s Opteron-based supers with Nvidia’s GPU coprocessors to make a more energy-efficient super – weighing in at a top speed of 20 petaflops when (and if) it is fully extended with GPUs.
![]() Rather than just throwing out the existing “Jaguar” supercomputer, Oak Ridge is doing what it has done in the past – and what the Cray supercomputers are designed to undergo – a timely upgrade. Oak Ridge did a two-step upgrade from XT3 to Xt4 systems for around $200m to get to the initial Jaguar configuration, which was rated at 263 teraflops of sustained performance on the Linpack Fortran benchmark test commonly used to rank the performance.
Rather than just throwing out the existing “Jaguar” supercomputer, Oak Ridge is doing what it has done in the past – and what the Cray supercomputers are designed to undergo – a timely upgrade. Oak Ridge did a two-step upgrade from XT3 to Xt4 systems for around $200m to get to the initial Jaguar configuration, which was rated at 263 teraflops of sustained performance on the Linpack Fortran benchmark test commonly used to rank the performance.
The current Jaguar machine consists of a mix of Cray XT4 and XT5 cabinets using six-core Opteron HE processors with a total of 224,256 cores and 362TB of main memory. The Jaguar server nodes are linked by the “SeaStar2+” XT interconnect and deliver 2.33 peak theoretical petaflops and 1.76 petaflops sustained on the Linpack test. This machine has 18,688 nodes, each with two Opteron processors.
The Titan system, also known as the OLCF-3 system in Oak Ridge-ese, will be based on the Cray XK6 ceepie-geepie, announced in May. The XK6 swaps out one of the Opteron processor sockets on the four-node XE system blade and puts in four of Nvidia’s Tesla X2090 GPU coprocessors and a chipset that implements a PCI-Express 2.0 link between the Opteron G34 sockets and the Nvidia GPUs.
Each Opteron socket has four memory slots sporting DDR3 main memory. (Cray currently supports 2GB and 4GB sticks, but can use fatter memory if customers wish to do so.) Cray is not shipping the XK6 machines with the existing 12-core “Magny-Cours” Opteron 6100 processors, but is rather waiting for Advanced Micro Devices to get the 16-core “Interlagos” Opteron 6200 chips out the door. AMD has begun shipping them to OEM customers (and presumably Cray is at the front of the line), but the Opteron 6200s have not been formally announced yet.
 Cray’s Tesla X2090-equipped XK6 system board
Cray’s Tesla X2090-equipped XK6 system board
The XK6 is based on the “Gemini” XE interconnect, just like the XE6 Opteron-only supers upon which they are based. That interconnect, which debuted in May 2010, is the heart of the XE6 and XE6m supers, implemented in 3D torus and 2D torus interconnects respectively on those two families of machines.
The Gemini interconnect has a lot more bandwidth than the SeaStar2+ interconnect and with about one-third the latency for hops between adjacent nodes, which results in the XE6 machine being able to pass about 100 times the messages between nodes. This is key for the message passing interface (MPI) protocol underlying most parallel supercomputer apps. And as you can now see, it will be key for the XK6 ceepie-geepie machines, since the GPUs are going to be able to do more math than the CPUs they are lashed to. A lot more messages are going to be flying around as calculations get done more quickly.
Under the plan Oak Ridge has put together to upgrade the Jaguar system to the Titan machine, the first thing that will be done is that all of those 18,688 two-socket nodes will be replaced with 4,672 four-socket hybrid XK6 blade servers. The net result will be a machine with 299,008 Opteron cores and – depending on the clock speeds AMD can deliver – probably somewhere between 25 and 30 per cent more raw x86 flops in the system … and presumably better performance given the faster interconnect. The machine will also have 600TB of main memory, which will not hurt performance, either.
Before the end of this year, 960 of the current Tesla X2090 GPUs will be added to the Titan system (in about one-twentieth of the system nodes). Eventually the future GPU coprocessors from Nvidia based on the “Kepler” GPUs – due later this year if all goes well – will also be added to the machine, according to Steve Scott, who is the new CTO of the Tesla GPU line at Nvidia.
GPU will use one-eighth the juice of a CPU to deliver each flop
Scott, you will recall, is the former CTO at Cray and has been intimately involved with several generations of Cray interconnects and system designs. By the end of 2012, when Titan is finished, the Kepler GPUs will account for around 85 per cent of the aggregate flops in the machine, says Scott. The expectation is that a single Kepler GPU coprocessor will deliver 1 teraflops of double-precision. But the important thing, says Scott, is that a GPU delivers each flop for about one-eighth the juice of a CPU.
“I am not dissing CPUs,” says Scott. “But they are designed to run single threads as fast as possible, which will be important for serial work. But we need something that is fundamentally low power for calculations, and that is the GPU.”
Oak Ridge is publicly hedging on the flops that Titan can deliver, saying the machine will be between 10 and 20 petaflops of peak theoretical performance. But clearly, with 18,688 Kepler GPUs, you get 18.7 petaflops right there. And there’s probably going to be at least 3 petaflops on the Opteron side. That gets you to over 20 petaflops peak. The reason that Cray, Nvidia, and Oak Ridge are hedging on the petaflops is that on Linpack tests done on several large ceepie-geepie systems thus far, more than half of the peak gigaflops in the system have gone up the chimney.
Oak Ridge has secured $97m in funding to upgrade Jaguar to Titan. The upgrade from the XT5 nodes to the XK6 nodes and the swapping out of the old Opteron processors for the new Opteron 6200s will be completed this year and generate $60m of revenues for Cray.
The addition of the Kepler GPUs plus other services to be performed by Cray represent the remainder of the contract, which will be completed in the second half of 2012. (Maybe those Kepler GPUs aren’t coming this year, eh?) The contract has upgrade options beyond these two phases, which probably include swapping out Opteron processors or GPUs, which could generate even more money for Cray and/or Nvidia.
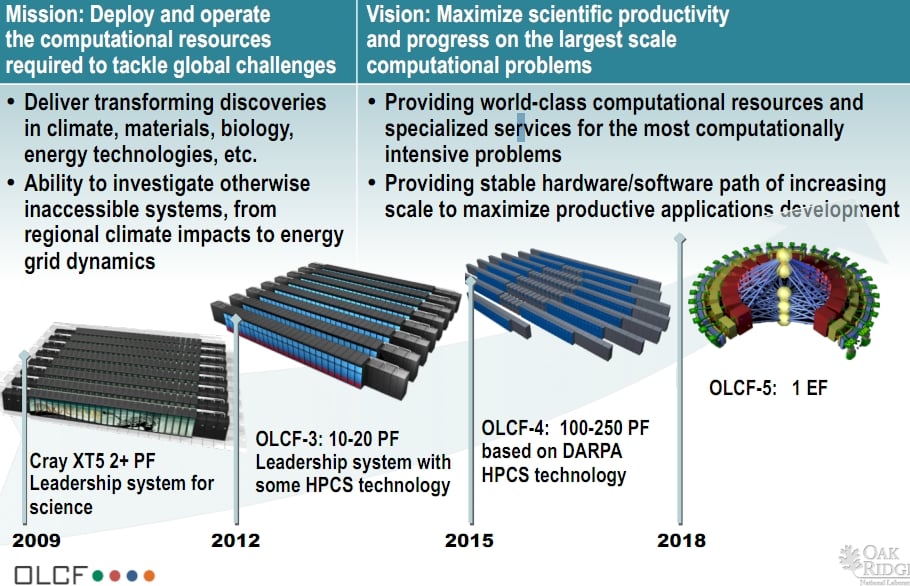
ORNL’s “Titan” OLCF-3 system is two steps away from exaflops (click to enlarge)
Oak Ridge has plans to get to get well above 20 petaflops. The OLCF-4 system, which is due in 2015, will scale from 100 to 250 petaflops and will be based on the “Cascade” system design that the US Defense Advanced Research Projects Agency is paying Cray to develop. The Cascade system will use the future “Aries” interconnect and will link nodes and coprocessors together through PCI-Express links and will support both AMD Opteron and Intel Xeon processors as compute nodes. It will probably also support a variety of coprocessors, including GPUs and FPGAs, too. Out in 2018, with the OLCF-5 design, it looks as if Cray is moving to a new network structure and hopes to hit an exaflops.
And yes, it will be able to play Crysis. But will it be able to play budget crisis? That is the real question. ®
This article originally appeared in The Register. It appears here in its entirety as part of a cross-publishing agreement.

