
Recently, insideHPC featured an interview with IBM’s Jay Muelhoefer on the topic of software defined infrastructure. To learn more about the storage sign of that coin, we caught up with Jim Gutowski and Scott Fadden from IBM.
insideHPC: Today I wanted to drill down on IBM Spectrum Scale. We used to know of this as GPFS. Can you tell me more?

Spectrum Scale Marketing Manager, IBM
Jim Gutowski: Well, thanks Rich. Yes, you’re exactly right. Spectrum Scale is the new name for GPFS, which is the General Parallel File System from IBM that’s been around about 15 years. It’s used in thousands of customers and has its roots in High-Performance Computing. We’ve expanded its capabilities and we’re also taking it into new markets like big data and analytics, which are very much like HPC, as you know.
We renamed it Spectrum Scale as part of IBM’s introduction of software defined storage. It’s a new category that’s emerged in the last few years. We have a family of products called IBM Spectrum Storage that does data management, virtualization, backup, archive, lots of capabilities across this family in software. It runs on a variety of hardware. So part of that we’ve renamed Spectrum Scale and added new capabilities to the product in this new software defined storage area.
insideHPC: So Jim, one of the things I found interesting about the announcement, was the idea that the Spectrum Scale software could run on other vendor’s hardware.
Jim Gutowski: That’s correct. It’s been available as software that runs on a variety of hardware. It runs on IBM of course, but it also runs basically on any x86 platform. It runs on AIX, Linux, Windows and uses virtually any storage device to store your data. So it’s truly hardware independent. Now, we do have an offering from IBM that bundles Spectrum Scale software with IBM servers and storage. We call that the Elastic Storage Server, and that’s an appliance like solution with a graphical user interface, ready to plug and play. So it’s a very nice way to implement Spectrum Scale as an option.
insideHPC: So Jim, what’s driving this? Why is IBM broadening this storage offering?
Jim Gutowski: Well since we have these slides, I’m going to move to slide number two here, and talk about the change that’s happening in the market that’s driving all this. The change is probably obvious to all the listeners out there, is this data explosion. People sometimes call it the internet of things. So lots of smart devices out there providing much more data that we want to take advantage of, and analyze and act on. We’re seeing it not just in the internet of things but also in applications like Facebook, Twitter, all of these mobile and social applications that are generating mountains and mountains of unstructured data. Voice data, video data, text data. How do I handle all of that data as I try and take advantage of it as a company moving into this new era?
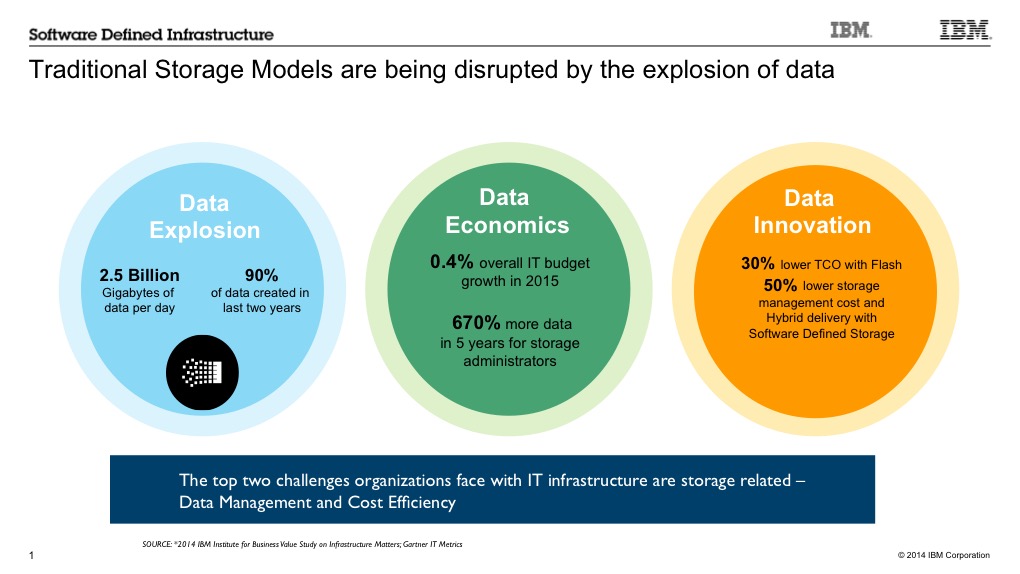 As we look at this chart, you see a couple of things that I’ll point out briefly. In the middle, data economics. So this massive amount of data is coming, as it says here, 670% more data that storage administrators have to deal with, but their budgets aren’t growing to accommodate it, so I’ve got to be smarter about how I manage all this data. Some of the things that we’re seeing, on the right, are things like software defined storage, that let you put more intelligence in the software and use commodity hardware devices to store the data. We’re also seeing the emergence of flash. So flash is becoming much more cost-effective and providing some tremendous performance benefits and driving down cost of ownership. So, as we help customers take advantage of these technologies, we’re adapting our software to do so.
As we look at this chart, you see a couple of things that I’ll point out briefly. In the middle, data economics. So this massive amount of data is coming, as it says here, 670% more data that storage administrators have to deal with, but their budgets aren’t growing to accommodate it, so I’ve got to be smarter about how I manage all this data. Some of the things that we’re seeing, on the right, are things like software defined storage, that let you put more intelligence in the software and use commodity hardware devices to store the data. We’re also seeing the emergence of flash. So flash is becoming much more cost-effective and providing some tremendous performance benefits and driving down cost of ownership. So, as we help customers take advantage of these technologies, we’re adapting our software to do so.
insideHPC: So a question for you, Scott. Does business really need a parallel file system? Does it really need that kind of data rates to get the job done?

Scott Fadden, Technical Marketing, IBM
Scott Fadden: Yeah, it really does Rich, and that’s one of the things where we’ve been very successful over the last number of years, is that there’s a lot of workloads, and Jim mentioned analytics. Analytics requires very high IO throughput. Lots of reads, lots of writes, very fast real-time data. That isn’t achievable using technologies like NFS and the standard NAS protocols.
So where this becomes valuable is in two dimensions. One is in the speed of data access. The parallel file system is very good at that, grew up in that environment. It does that very well. The other things just the raw capacity. In a Spectrum Scale file system, we have file systems of 20 petabytes or larger. These are new scales that NAS appliances don’t get close to. So, these are the dimensions that really have been driving this technology.
insideHPC: Okay, so you’ve brought this HPC technology to business markets. What have you added to what we knew as GPFS to bring about Spectrum Scale?
Scott Fadden: Well, there’s two things. One, we’re talking about features that have been there for years. The people hadn’t been using these features in HPC very much, but they have been very popular with our commercial customers.
The second thing is the ecosystem and environment around it. For example, one of the areas that we’ve been doing a lot of work on is, what we call the protocols. We’ve had NFS, and Object for awhile. We’re adding CIFS. The intent is to be able to share all this in one set of hardware, and be able to scale it up. So we’re adding more access to the data. We’re adding hub integration. We’re adding usability and monitoring tools that our customers have been asking for. The Spectrum Scale directive is more holistic than it was before with just as GPFS.
insideHPC: So if I have existing infrastructure out there, like a lot of data centers of course do, can I put this Spectrum Scale software on top of all that?
Scott Fadden: Absolutely. This is where software defined infrastructure and specifically software defined storage, is really making it into the market. That is customers no longer want to toss out everything and put in something new. Especially when you’re talking about data, because migrating a lot of data, to replacing a lot of things. What if you can reuse what’s already there? With the software for example you have the ability, as Jim mentioned, to use x86 or power hardware. There are lots of different operating systems you can run this on. We can use any block storage device. So we can use existing storage. We can even integrate with existing NFS storage. So, you don’t have to move everything off of NFS to use this in your environment for example. We’ve done a lot of work to leverage existing infrastructure.
Jim Gutowski: Right, and Rich there’s good reason to do it. We had a customer on stage at a recent event from Cypress Semiconductor, high-performance computing doing electronic design simulation, not running IBM hardware. They tried Gluster to replace their NFS file system, to get some better performance, that didn’t work very well. So they installed spectrum scale on their existing hardware, and got a 10x performance improvement, running on the same hardware, taking advantage of the peril and capabilities that we deliver for these type of applications. Absolutely we run another hardware.
insideHPC: Great. Scott, I wanted to ask you about this globe you have in the diagram there, this idea of off-premise storage. How does that scenario work?
Scott Fadden: There’s a number of different things we’re doing in the area to be able to move data off-premise. Today for example, we have the count of the storage tiering. So you can store between different– or tier move data transparently between different types of direct access storage devices, things like spinning discs or flash. We can move it to tape, and tape to be onsite or offsite, because this can be onsite or offsite. We’re taking that to the next dimension. We already have with the technology, we call active file management, which allows us to put copies of data in other locations. They synchronously across site. Where we are moving with this, is to be able to take that offsite capability, and put it into any standard cloud infrastructure whether that would be IBM cloud or Amazon, or something else. We’ll be able to migrate that data into and out of the cloud transparently for the user. This will allow people to leverage cloud economics without having to redo their applications or their internal infrastructure.
insideHPC: Well, Scott of course, we live in a world with a lot of technologies are sprouting up–new companies with flash technologies and all this other stuff. But it seems to me that the with the enterprise, where data has to be there forever, this would seem to be the space where IBM is really going to play well.
Scott Fadden: Well, that’s exactly the environment where we do well. We have customers who have been running this for over ten years that had never had to throw out everything and put in new stuff. They’ve migrated new hardware and things over time, and the data moves on the background – that sort of thing. The other things that I just talked about was a lot of the effort to put integration with other things, and existing NFS servers with Clouds. Our intent is to be able to live in an existing environment and be able to migrate technologies over time without having to move all your data, throw it out or re-do all your data infrastructure.
insideHPC: So, Scott, I wanted to ask you about the software defined piece of this, and this idea of a single name space. Is the world moving towards an all object storage? Is this inevitable?
Scott Fadden: Every new technology is inevitable. We would all like to say that everything will be on Object in x amount of years. We don’t know that. But we support Object today for that reason. We know people have needs for Object. We know the economics. We know the benefits. But what we’re seeing right now in the industry is not everything’s there. Not everything works off of Object storage. Yes, Object is responsible for lots of petabytes of data. There’s absolutely no doubt there. Does it do everything or will it do everything? I don’t know.
insideHPC: Great. Jim, any closing thoughts folks that might be out there looking at Spectrum Scale?
Jim Gutowski: Yeah, thanks Rich. Let me just again, touch on some of the key things that we’ve talked about. You mentioned the global name space. Certainly, that’s important as you move data among multiple sites, or around the world, or archive it off. It should be nice to see that data wherever it is. We enable that with Spectrum Scale. Scott mentioned this policy based tiering capability.
We have a great customer example. I was just at a conference where Nuance Communications spoke with us. They do Dragon Naturally Speaking. They do the voice recognition in your cell phone and in your car. They’ve been using Spectrum Scale for years. They’ve got about six petabytes of storage. They do this policy based tiering. They move the hot data that they’re working on at a particular time, to faster storage. They’re using solid-state discs. You could use flash. You could use faster discs. But automatically move that hot data to accelerate my analytics, my applications and then when it’s done – when it’s cold, if no-one’s touching it – we can move it off to lower-cost tiers or to tape, or other storage.
So there’s some really powerful capabilities that have been in the product for a long time, we continue to enhance it. It’s enterprise ready. It’s proven in a marketplace, so very strong product. It’s open. It’s posits compliant, so you can run your Hadoop workloads on it, and still use it for other applications very easily. So lots of benefits in Spectrum Scale. As part of this Spectrum Storage family, IBM announced a billion-dollar investment in this family of products over the next five years. So you’ll continue to see us enhance the product and improve it, and add capabilities over time. So IBM is a solid partner for helping you manage data at scale with Spectrum Scale.
Learn more about IBM Spectrum Scale. * Watch the Slidecast * Sign up for our insideHPC Newsletter.
