 In many large threaded applications, synchronizing all of the threads by use of barriers can results in significant wasted processing time. If the application lends itself, loosely synchronous barriers instead of strictly synchronous barriers should be used and can recover lost time.
In many large threaded applications, synchronizing all of the threads by use of barriers can results in significant wasted processing time. If the application lends itself, loosely synchronous barriers instead of strictly synchronous barriers should be used and can recover lost time.
An application that simulated diffusion of a solute through a volume of liquid over time in a 3D container. Initially, a number of steps were taken to optimize performance.
- Baseline – a single threaded version of the application
- OpenMP – use OpenMP to parallelize the application where applicable
- Vectorization – add simd vectorization to the application
- Peel – remove unnecessary code from inner loops
- Tiled – partition the data to improve cache hit ratios
Using the above mentioned optimizations, the performance of the application sped up over 500X from the initial Baseline run. However, there is more to do to achieve lower run times. A number of different methods were looked at and tried in order to increase the performance.
Hyperthreading and determining the hyperthreading within a core were examined. Data alignment was determined to have an effect on the execution Calls to malloc were changed to use _mm_malloc with an alignment to cache line size of 64.
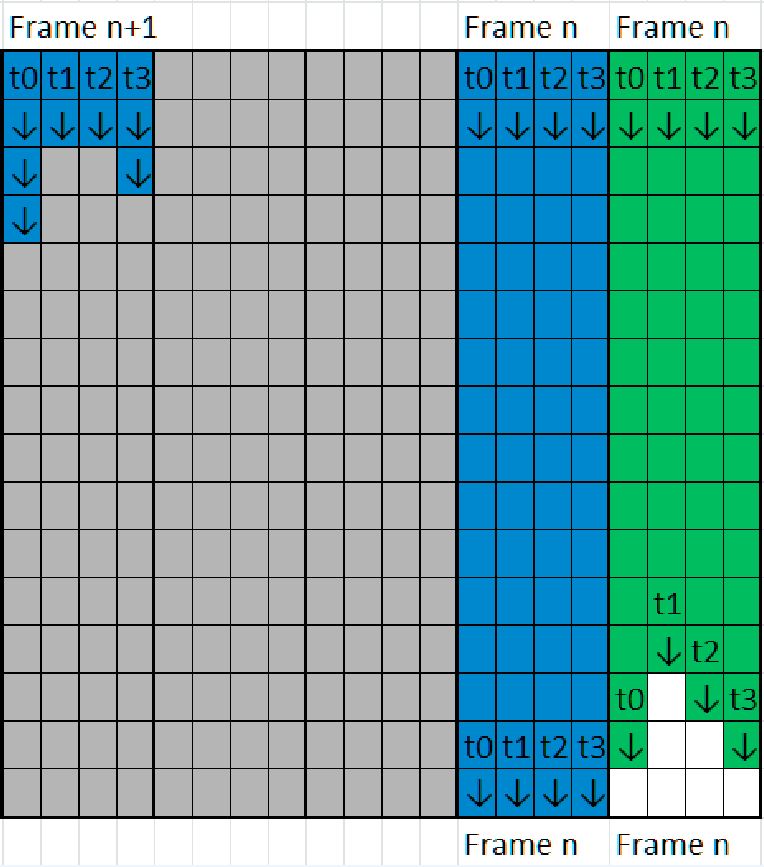
As each of the threads performed work, it was discovered that some of the cores were waiting for more work to be assigned and just wasted time waiting for all threads to complete their work. The solution to this was to use a core barrier in place of a thread pool barrier. Using this technique, a thread that has finished can then pick up more work, and begin processing before the other cores reach the barrier. In one implementation, this is called the plesiochronous barrier.
The performance gains using this method was up to 15X compared to the original OpenMP version, on both 256 x 256 grids and 512 x 512 grids, on the Intel Xeon Phi 5110P coprocessor. On the host system, consisting of the Intel Xeon E5-2620 v2 processor, the Gflops were increased from about 10 to over 50 for the larger grid. Many presume that using 2 threads per core will generally decrease performance on floating point intensive programs. However, the use of the Plesiochronous Hyper-Thread Phalanx disproves this assumption.
Source: QuickThread Programming, LLC, USA

