Sponsored Post
This is the second in a series of articles on “6 Things You Should Know About Lustre”. Other topics cover Lustre in Enterprise, the Cloud, Financial Services, and next-generation storage.
By 2020 Gartner predicts as many as 25 billion devices[i] will be connected to the Internet, as the Internet of Things (IoT) erupts with an unending stream from wearables, smart vehicles, smart appliances, smart everything that can offer consumer data to enterprises and potentially reveal entirely new insights through analytics. Until then, EMC estimates data will double every two years, resulting in every man, woman, and child on the planet generating about 5.2 terabytes in 2020 alone[ii].
Hadoop* has emerged as the framework designed to enable companies to leverage this rising tide of information. But companies already using High-performance Computing (HPC) with a Lustre* file system for simulations, such as those in the financial, oil and gas, and manufacturing sectors, want to convert some of their HPC cycles to Big Data analytics. This puts Lustre at the core of the convergence of Big Data and HPC.
“HPC and Big Data convergence is very recent,” say Ute Gojrzewski, of Intel’s High Performance Data Division (HPDD). “So we are coming up with ways to make it efficient and performant. We want to show customers how well Big Data can run on HPC.”
Intel has added two components to its Intel® Enterprise Edition for Lustre* software to help accelerate this convergence. According to Gabriele Paciucci, a Solutions Architect for Intel HPDD, they are seeing up to 3X speedup in Hadoop jobs running on HPC clusters in their Swindon, U.K. lab with Lustre compared to running on HDFS using their software.
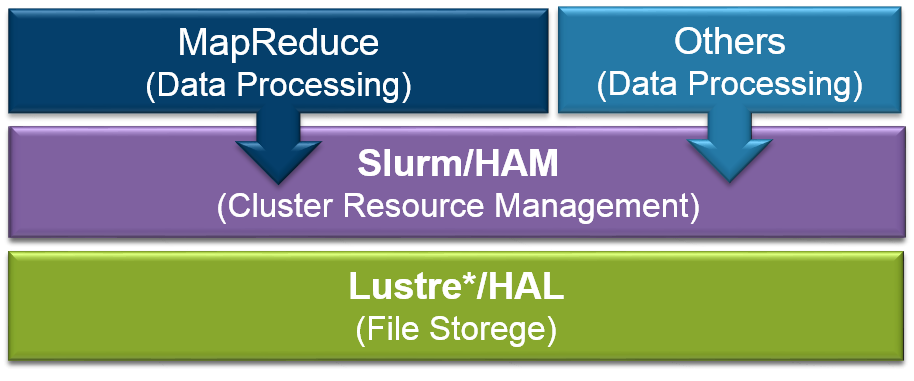
Meet HAL—HPC Adapter for Lustre
Intel developers have written a file system interface to Hadoop called HAL (Hadoop Adapter for Lustre) that replaces HDFS with Lustre. With HAL, Hadoop behaves as if it’s reading from and writing to HDFS. HAL removes the need for replicated local storage and the work necessary to convert data from Lustre to the Hadoop Distributed File System (HDFS).
Meet HAM—Hadoop Adapter for MapReduce
Hadoop is essentially a workload manager for Hadoop’s MapReduce process, which spreads the work out over a cluster, maps the data, shuffles it horizontally across the nodes, reduces it down, and digests the results. To run Hadoop on HPC, Intel has made Hadoop jobs look like any other HPC job by creating a specially written interface to the HPC Slurm (Simple Linux Utility for Resource Management) job scheduler. The Intel connector is called HAM, which stands for HPC Adaptor for MapReduce.
Eliminating the Hadoop Shuffle
The two adapters have an important impact on Hadoop’s shuffle phase, which might need to move hundreds of terabytes of data across a cluster, a time consuming process even over a 10 gigabit Ethernet wire. With HAM and HAL, Hadoop writes all the data to a globally accessible Lustre data store at up to 2 TB/sec, removing the need to communicate sideways to share the results. The shuffle part of MapReduce simply disappears. For Reductions, MapReduce just reads the results back. That delivers a significant savings in terms of time to solution.
Leveraging Big Data Today
The convergence of Big Data analytics on HPC is just beginning. But, with HAM and HAL and the work Intel has done in their Intel Enterprise Edition for Lustre software, companies can begin adopting analytics written for Hadoop and run them on their HPC clusters. The potential benefits are huge, considering the expense and expertise required to set up and manage Hadoop clusters with dedicated storage. Enterprises with available HPC cycles and their data in Lustre can take advantage of their existing infrastructure and start leveraging Big Data analytics now.
Learn more about Intel® Lustre products >
[i] http://www.gartner.com/newsroom/id/2905717
[ii] http://www.emc.com/leadership/digital-universe/2012iview/executive-summary-a-universe-of.htm

