
The following best practices can be used to maximize GPU resources in a production HPC environment. The approaches can be broken down into six strategies that address the issues mentioned in the first article in this 5 part series.

Download the insideHPC Guide to Managing GPU Clusters
This is second article in series on ‘managing GPU clusters.’ You can read the entire series or download the complete insideHPC Guide to Managing High Performance GPU Clusters courtesy of NVIDIA and Bright Computing.
Strategy 1: Provide a Unified System so Users/Developers can Focus on Results/Coding
HPC developers want to write code and create new applications. The advanced nature of HPC often requires that this process be associated with specific hardware and software environment present on a given HPC resource. Developers want to extract the maximum performance from HPC hardware and at the same time not get mired down in the complexities of software tool chains and dependencies. For instance the workload scheduler should be GPU-aware and not force the users to figure out how to use and share GPU resources.
To address this need, the entire HPC resource needs to be treated as a “system“ and not a collection of hardware stitched together by shell scripts and incompatible cluster management tools. Four factors that should be addressed include:
- Provisioning – the cluster needs to have the flexibility to provision nodes based on specific hardware and software requirements. All valid and tested combinations should be available to users without creating extra work for systems administrators.
- Workload Managers – Cluster workload managers such as Slurm, PBS Pro, Torque/Maui/Moab, Grid Engine, and LSF should be integrated and be aware of all resources in the cluster – including both CPUs and GPUs.
- Comprehensive monitoring – End users should not have to concern themselves with system monitoring. That is, they should not have to log in to individual nodes, check loads or run tools like nvidia-smi to be assured their applications are working properly. Administrators should not be “figuring out“ how to collect this data for each type of hardware in the cluster. In addition, pre-job health checks should be automatic so that user jobs are not schedule to run on failing or distressed hardware.
- Development Tools – The entire development tool-chain must be integrated and flexible. Any dependencies must be addressed and not left as “an exercise for the users.” These tools include compiler, libraries, debuggers, and profilers that users need to develop code.
Without attention to the above four aspects, users can expect delays and increased time to solution. In addition, system administrators must manage ever-increasing complexity as systems change. Fortunately, each aspect mentioned above can be managed automatically with Bright Cluster Manager™. It provides leading edge and comprehensive cluster management capabilities for any HPC cluster including those equipped with NVIDIA GPU accelerators. The approach is top-down and fully integrates the underlying hardware into a true HPC resource — ready for users.
Bright provides both point and click and scriptable command line control of the entire cluster. These capabilities create a flexible provisioning management where any popular Linux distribution (SUSE, Red Hat, CentOS, Scientific Linux) can be loaded onto any node. In addition, specific kernel versions and GPU kernel modules can be easily managed. These capabilities can all be managed using Bright Cluster Manager’s “single pane of glass“ graphical management console. Every aspect of the cluster, both local and in the cloud is managed in a consistent and intuitive fashion. As an example GPU integration Figure 1 shows how administrators can have direct access to the performance-enhancing NVIDIA GPU Boost technology.
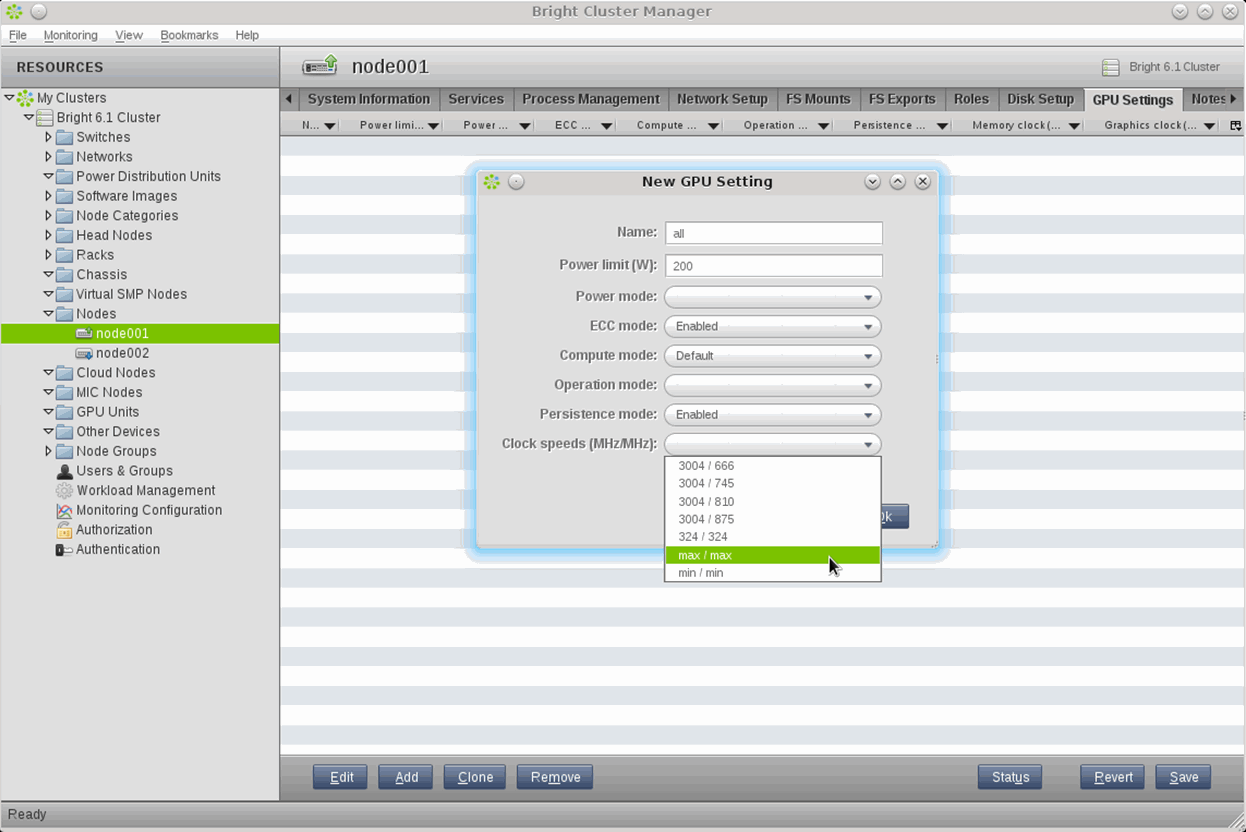
Figure 1: Bright Cluster Manager manages NVIDIA accelerators used in hybrid-architecture systems for HPC. Bright allows direct access to the NVIDIA GPU Boost technology through clock-speed settings.
Strategy 2: Automate Updates
Keeping track of available GPU software updates can be a burdensome process. Integrating and testing updated software capabilities can introduce delays and broken development tool chains. When performing these types of updates, functional testing is required to make sure everything that worked previously continues to work correctly. If multiple generations of GPU hardware are present, more detailed testing might be needed to ensure the new environment “just works.” Developers appreciate clean updates and dislike broken environments. Simply installing GPU updates and hoping for success is a recipe for disaster.
A good way to address software updates is to install and test in a non-production sandbox environment. The sandbox should have the exact same hardware environment as production nodes. Only when the software updates have been tested should the productions nodes be re-provisioned and any updated or new development tools be made available. The more this process can be scripted or automated the easier it will be to perform for subsequent updates. As part of the scripting process, all kernel modules and drivers should be built with the same production kernel (or kernels) running on the cluster and should include automated testing of the new environment.
An alternative to building and managing a custom local GPU sandbox is to use a comprehensive cluster manager. Bright Cluster Manager provides automatic synchronization with the latest NVIDIA CUDA software (verified for your environment). The synchronization includes a full update and install of any new NVIDIA software versions including the administrative steps required for full operation. This process includes building any kernel modules, rebooting/provisioning cluster nodes, and functional testing with both CUDA and OpenCL test code (Test applications are built and executed on the environment).
This feature actually goes deeper than automatic updates. NVIDIA works closely with Bright to provide early access to drivers, CUDA updates, and new GPUs so that when the Bright updates are released, your cluster is ready with the latest software and hardware from NVIDIA. When a new version of CUDA is released, new Bright CUDA packages are made available for all recent Bright versions as soon as possible, after QA tests. Because Bright follows the CUDA release cycle, the Bright cluster manager will ensure updates are current and work as expected. These updates include full integration of any new capabilities into the monitoring layer of Bright Cluster Manager. The process provides developers with smooth and uninterrupted use of the cluster and eliminates the need for administrators to create and manage a sandbox test environment.
Next week we’ll dive into strategies for managing user environments and and providing support for GPU programming. If you prefer you can download the complete insideHPC Guide to Managing GPU Clusters courtesy of NVIDIA and Bright Computing.

