This is the fifth article in a series on six strategies for maximizing GPU clusters. These best practices can will be helpful as you build plans for cloud based GPU processing.

Download the insideHPC Guide to Managing GPU Clusters
The cloud is here and ready to start running HPC applications. Certainly the cloud is not a one size fits all solution, but many organizations have found great utility in using both public and private clouds as a computing resource.
The public cloud providers, like Amazon Web Services, that offer systems with NVIDIA GPUs. Thus, it is possible to provide both local and cloud based GPU computing. An in-house private cloud could also be used as a HPC resource. Bright Cluster Manager provides and integrated OpenStack option from which private clouds can be easily created and managed. A cloud HPC strategy can range from a plan to provide local overflow resources to a full-fledged offsite GPU cluster in the cloud.
For some applications, cloud based clusters may be limited due to communication and/or storage latency and speeds. With GPUs, however, these issue are not present because application running on cloud GPUs perform exactly the same as those in your local cluster — unless the application span multiple nodes and are sensitive to MPI speeds. For those GPU applications that can work well in the cloud environment, a remote cloud may be an attractive option for both production and feasibility studies.
Integrating a cloud solution into an in-house cluster can be difficult because the cloud only provides the raw machines to the end users. Similar to an on-site cluster, the GPU cloud cluster needs to be configured and provisioned before use. All of the issues mentioned previously — everything from CUDA drivers and libraries to a managed and integrated development environment — must be available as part of the cloud resource. Expecting developers to use or design for a different software environment creates extra work and expense. Indeed, flexibility and ease of management is now even more important in the cloud due the ephemeral nature of GPU cloud clusters, (i.e., administrators may need to repeatedly set up and tear down cloud instances over time). Long lead times for custom cluster configuration defeats the advantages of an on-demand cloud environment.
In addition, because cloud use is metered, it should be used as efficiently as possible. Trying to “get things working” in the cloud can be an expensive proposition. Wasted time, repeated configuration changes, testing, and frustrated users and developers all reduce the economics that made the cloud attractive in the first place.
The best strategy is to prepare for eventual cloud use and find those providers that support your type of GPU computing hardware. Once identified, determine a method to translate the current local configuration to the cloud hardware and then test to make sure everything works as expected.
An integrated solution like Bright Cluster Manager can provide a managed and transparent cloud-based GPU cluster. The same powerful cluster provisioning, monitoring, scheduling and management capabilities that Bright Cluster Manager provides to onsite clusters extend into the cloud, ensuring effective and efficient use of the virtual cloud resources. Using Bright Cluster Manager, you can extend into public GPU clouds, such as AWS, with only a few mouse clicks. There’s no need for expert knowledge of Linux or cloud computing. The exact same administration interface is used for both local and cluster nodes. Installation/initialization, provisioning, monitoring, scheduling and management are identical. There is no learning curve required for cloud HPC use.
There are two possible scenarios available with Bright Cluster Manager. The first is a “cluster on demand,“ shown in Figure 4 that can be created in the cloud as a fully functioning GPU cluster. Again, depending on the application, this cluster will behave, from a software standpoint, exactly like a local GPU cluster.
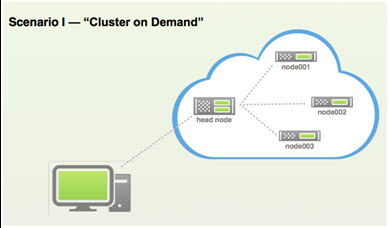
Figure 4: Bright Cluster Manager can create fully functioning ready to run GPU clusters in the cloud.
The second use case it that of a “cluster extension,“ shown in Figure 5. In this example, the cloud is used to extend the local resources. In either scenario the cluster is manage directly from the Bright Cluster Manager interface. There is no need to apply any special provision to the cloud nodes.
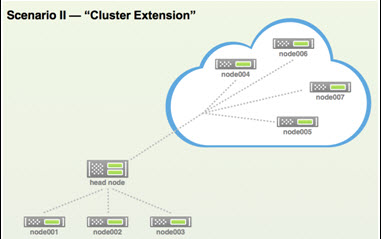
Figure 5: An internal or external cluster extension can be created using Bright Cluster Manager. The new remote cluster resources are mange exactly the same as cluster nodes.
Next week we’ll take look at a case study on cloud based GPU processing. If you prefer you can download the complete insideHPC Guide to Managing GPU Clusters courtesy of NVIDIA and Bright Computing.


There are a number of otherpurpose-built HPC cloud providers like ours, Nimbix, which have been perfected this offering for years now with NVIDIA GPUs available on-demand in the cloud. Other alternatives exist besides AWS and Bright who provide minimal elasticity and customer service is subpar by Enterprise customer standards.