This is the forth article in a series on six strategies for maximizing GPU clusters. These best practices can will be helpful as you plan for the convergence of HPC and big data analytics .
Strategy 5: Plan for the Convergence of HPC and Big Data Analytics

Download the insideHPC Guide to Managing GPU Clusters
As an open source tool designed to navigate large amounts of data, Hadoop continues to find new uses in HPC. While traditional Hadoop applications do not run on GPU hardware, version 2 of Hadoop supports virtually any computing model or hardware environment. This flexibility allows Hadoop to be used for more than the traditional MapReduce applications and opens up many possibilities. In particular, breakthrough deep learning performance has been achieved with new algorithms and can be accelerated with GPUs. For example, NVIDIA provides the cuDNN library of primitives for Deep Neural Networks. Combined with the Big Data capabilities of Hadoop, GPUs offer a path to accelerated training of deep learning models.
Managing a Hadoop cluster is different than managing an HPC cluster, however. It requires mastering some new concepts, but the hardware is basically the same and many Hadoop clusters now include GPUs to facilitate deep learning. In one sense, a Hadoop cluster is actually simpler than most HPC configurations as they primarily use Ethernet and commodity servers. Hadoop is an open-source project and is often configured “by hand” using various XML files. Beyond the core components, Hadoop offers a vast array of additional components that also need management and configuration.
One solution that provides Hadoop capabilities to HPC clusters is to carve out a sub-cluster within the main cluster. The sub-cluster is a collection of nodes configured to run the various Hadoop services. Hadoop version 2 processing is different than the typical HPC cluster as it has its own resource manger (YARN) and file system (HDFS). Integration with an existing cluster can be somewhat tedious as a completely different set of daemons must be started on Hadoop nodes.
Instead of configuring and managing a sub-cluster or specialized Hadoop system, an automated solution such as Bright Cluster Manager can effortlessly bring Hadoop capability to a cluster. Bright Cluster Manager supports the leading distributions of Apache Hadoop (e.g., from the Apache Foundation, Cloudera, Hortonworks), enabling Bright’s customers to choose the one that best fits their needs while taking advantage of Bright Cluster Manager’s advanced capabilities. The same management interface covers the Hadoop nodes that can easily be configured to contain GPUs. As shown in Figure 3 below, Bright Cluster Manager provides an instance of a Hadoop running in the cluster. The view provides an overview of essential Hadoop parameters.
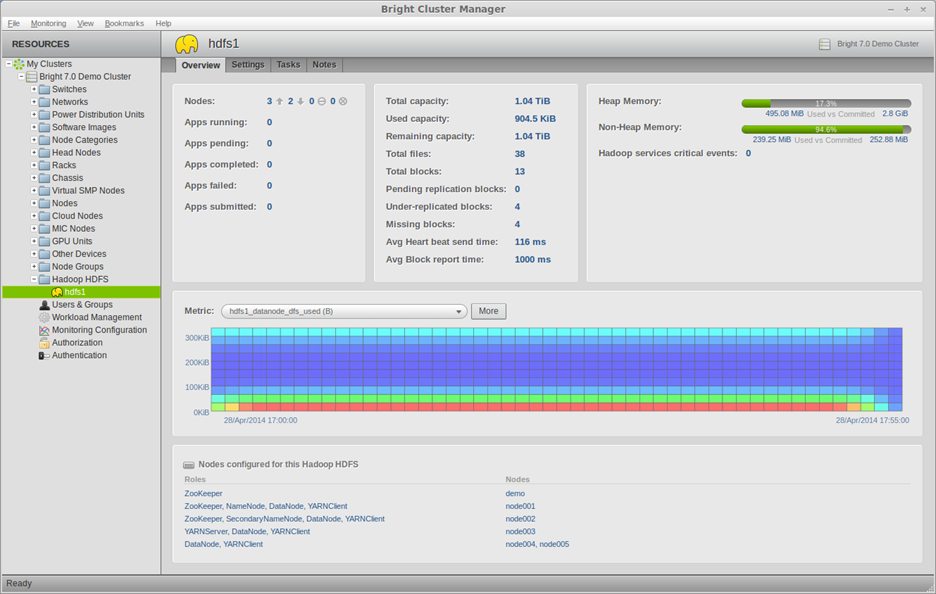
Bright Cluster Manager manages multiple instances of Hadoop HDFS simultaneously. Bright’s “Overview” tab for Hadoop illustrates essential Hadoop parameters, a key metric, as well as various Hadoop services.
Next week we’ll dive into strategies for developing a plan for cloud based GPU processing. If you prefer you can download the complete insideHPC Guide to Managing GPU Clusters courtesy of NVIDIA and Bright Computing.

