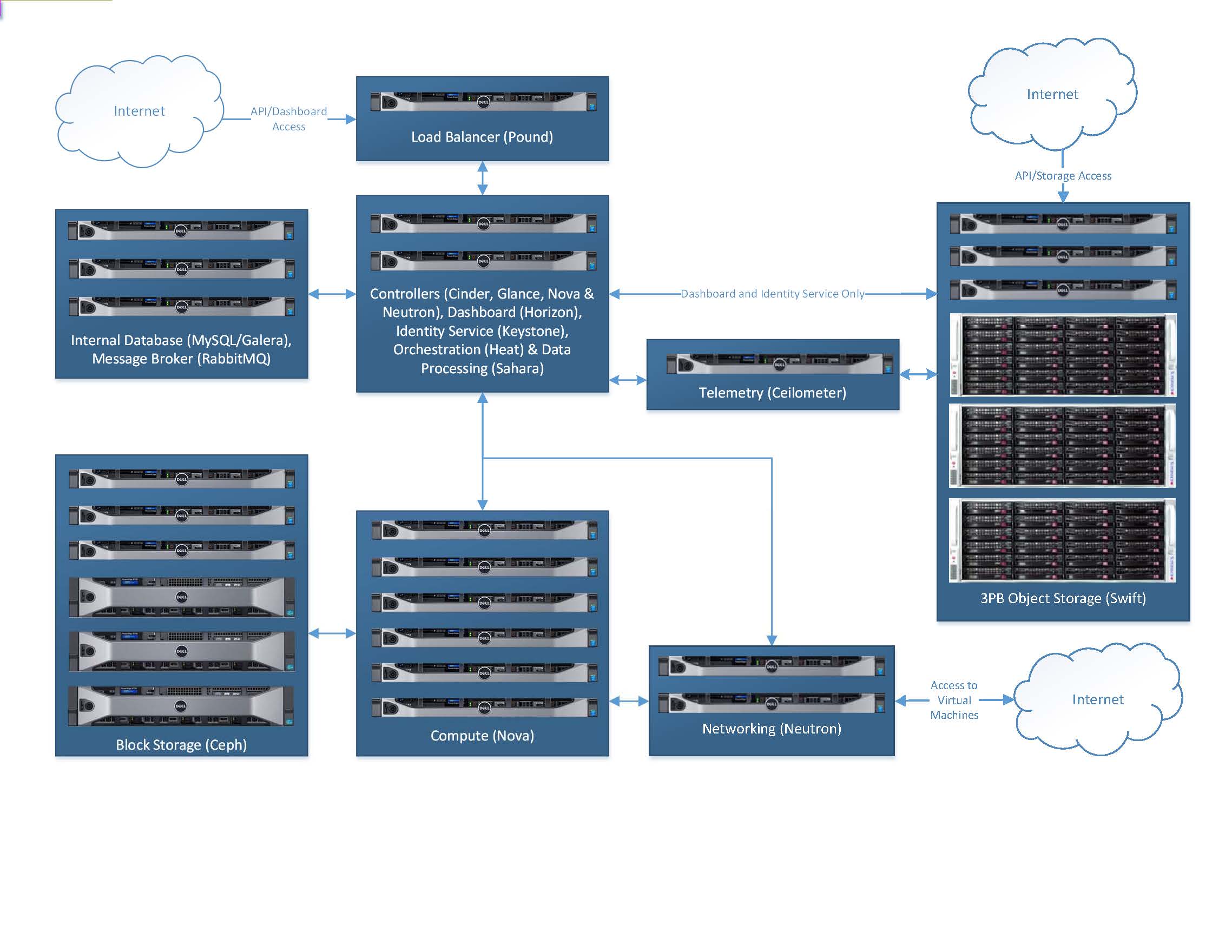

The reliable and scalable architecture of the SDSC Cloud was designed for researchers and departments as a low cost and efficient alternative to public cloud service providers. Image: Kevin Coakley, SDSC
Today the San Diego Supercomputer Center (SDSC) announced that it has made significant upgrades to its cloud-based storage system to include a new range of computing services designed to support science-based researchers, especially those with large data requirements that preclude commercial cloud use, or who require collaboration with cloud engineers for building cloud-based services.
The upgrades to SDSC Cloud, which debuted in late 2011 as one of the first large-scale academic deployments of cloud storage in the world, offers a unique storage service to educational and industry partners. The object-based storage system provides a highly scalable solution with flexible access methods and enhanced durability, while providing exceptional performance using high-speed 10 gigabit (Gb) connectivity at a fraction of the costs of other service providers.
In addition to a steadily growing user base of researchers, SDSC Cloud will also serve pilot projects for national initiatives such as the National Data Service (NDS), the National Science Foundation’s Big Data Innovation Hub, and other data science projects.
“We’ve added a number of significant enhancements, both on the service and support sides, that researchers who have to compute, store, or share massive amounts of data will appreciate,” said Christine Kirkpatrick, SDSC’s Division Director of IT Systems and Services. The latest upgrades include:
- Adding a compute facility to SDSC Cloud’s multi-petabyte storage environment. Customers can now have on-demand compute resources without acquiring their own hardware. Compute resources can be secured instantaneously for short periods, with the ability to snapshot and duplicate machines within a minute. This provides a facility for perfecting a software environment that others can benefit from, especially without having to set up new physical, specialized infrastructure. Customers can also make their images and recipes public for their community to deploy software packages without a larger orchestration environment. All of this resides within the SDSC ecosystem, with the ability to burst out to high-performance compute resources as dictated by individual use cases.
- Using the suite of OpenStack open-source cloud products, including the underlying identity management, software-defined networking, and orchestration components. Key benefits include unified identity management, the ability to integrate with third-party and external authentication services, APIs compatible with other computing platforms, as well as the ability to port compute images between other cloud-based platforms.
- The addition of OpenStack Sahara for instantiating Hadoop and Spark clusters. This benefits customers needing ‘Big Data’ processing technologies, but on an elastic compute resource.
- Upgrading interfaces to a cloud dashboard environment, allowing users to view both their storage and compute from one interface as well as utilization, statistics, and user software-defined networking capabilities, images, and snapshots.
- The expansion of a Cloud Consulting & Integration Team to assist users in onboarding, integrating, and consuming cloud resources. Working with this team, researchers can gain insights to optimizing and streamlining their platforms. SDSC Cloud also supports hybrid clouds, as well as uses of other clouds. A Cloud Broker is ready to assist with pricing various options, especially for academics needing pre-award, proposal documentation and cost-benefit analysis.
The emphasis is on supporting scientific customers, especially those with data requirements that preclude commercial cloud, who can also benefit from domain expertise or who want the added comfort of knowing they can directly interact with the cloud engineers for support,” added Kirkpatrick. “This is especially advantageous for customers not already consuming cloud services and who might need additional help integrating cloud into their workflows.”

