Today NERSC announced a collaboration with UC Berkeley’s AMPLab and Cray to design large-scale data analytics stacks.
Analytics workloads will be an increasingly important workload on our supercomputers and we are thrilled to support and participate in this key collaboration,” said Ryan Waite, senior vice president of products at Cray. “As Cray’s supercomputing platforms enable researchers and scientists to model reality ever more accurately using high-fidelity simulations, we have long seen the need for scalable, performant analytic tools to interpret the resulting data. The Berkeley Data Analytics Stack (BDAS) and Spark, in particular, are emerging as a de facto foundation of such a toolset because of their combined focus on productivity and scalable performance.”
The need to build and study increasingly detailed models of physical phenomena has benefited from advancement in high performance computing for decades. It has also resulted in an exponential increase in data, from simulations as well as real-world experiments. This has fundamental implications for HPC systems design, such as the need for improved algorithmic methods and the ability to exploit deeper memory/storage hierarchies and efficient methods for data interchange and representation in a scientific workflow. The modern HPC platform has to be equally capable of handling both traditional HPC workloads and the emerging class of data-centric workloads and analytics motifs.
In the commercial sector, these challenges have fueled the development of frameworks such as Hadoop and Spark and a rapidly growing body of open-source software for common data analysis and machine learning problems. These technologies are typically designed for and implemented in distributed data centers consisting of a large number of commodity processing nodes, with an emphasis on scalability, fault tolerance and productivity. In contrast, HPC environments are focused primarily on no-compromise performance of carefully optimized codes at extreme scale.

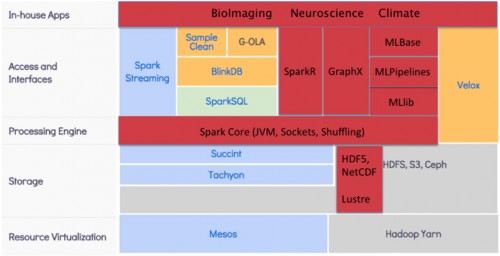
This chart highlights portions of the BDAS stack (in red) that will be explored as a part of the Cray/AmpLab/NERSC collaboration.
Given this scenario, how can we the derive the greatest value from adapting productivity-oriented analytics tools such as Spark to HPC environments? And how can a framework like Spark better exploit supercomputing technologies like advanced interconnects and memory hierarchies to improve performance at scale, without losing its productivity benefits?
To address these questions researchers from Cray, AMPLab and NERSC are actively examining research and performance issues in getting Spark up and running on HPC environments such as NERSC’s Edison (Cray XC30) and Cori (Cray XC40) systems. Since linear algebra algorithms underlie many of NERSC’s most pressing scientific data analysis problems, this collaboration will involve the development of novel randomized linear algebra algorithms, the implementation of these algorithms within the AMPLab stack and on Edison and Cori and the application of these algorithms to some of NERSC’s most pressing scientific data-analysis challenges, including problems in BioImaging, Neuroscience and Climate Science.
Drawing strength from NERSC’s expertise in scientific data applications, the collaboration combines grand challenge analytical problems from NERSC, pioneering research into big data platforms and scalable randomized linear algebra methods from AMPLab and Cray’s long-standing expertise in scalable supercomputing systems. “We are looking forward to understanding and improving the systems-level behavior and performance of Spark when it is applied to challenging real-world analytics problems on some of Cray’s biggest platforms to date,” said Venkat Krishnamurthy of the Analytics Products group at Cray, who is leading Cray’s involvement in this initiative.
“The AMPLab has been a great success in terms of infrastructure development, but we are continually on the lookout for new use cases to stress-test our framework,” said Michael Mahoney, a faculty member in the University of California, Berkeley Department of Statistics and AMPLab and lead principal investigator on the project. “Spark is very good for certain data analysis computations, but typical Spark use cases haven’t stressed many of the sophisticated linear algebra computations that underlie popular machine learning algorithms. This has historically been the domain of scientific computing. We aim to bridge that gap, to the benefit of both areas.”
There is currently a lot of momentum behind Spark in the commercial world, and we would like to explore how the scientific community can benefit from the resulting big data analytics capabilities,” said Prabhat, Data and Analytics Services Group Lead at NERSC. “Spark offers a highly productive interface for data scientists; the question in my mind is really regarding Spark’s performance and scalability. Historically, the HPC community has set a high bar for computing performance, and we are hopeful that this collaboration will lead the way in bridging the gap between big data analytics for commercial and high-performance scientific applications.”
Download the insideBIGDATA Guide to Scientific Research

