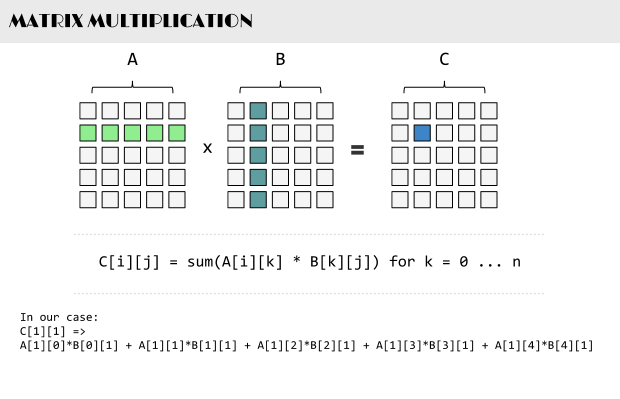
 Matrix multiplication is at the heart of many scientific applications and has been optimized to run on both the host Intel Xeon CPUs as well as the Intel Xeon Phi coprocessors. Matrix multiplies can be decomposed into tiles and executed very fast on the latest generations of coprocessors.
Matrix multiplication is at the heart of many scientific applications and has been optimized to run on both the host Intel Xeon CPUs as well as the Intel Xeon Phi coprocessors. Matrix multiplies can be decomposed into tiles and executed very fast on the latest generations of coprocessors.
Intel has developed the hStreams library that supports task concurrency on heterogeneous platforms. The concurrency may be across nodes (Xeon, KNC, KNL-SB, KNL-LB); within a node for small matrix operations; and in the overlapping of computation and communication, particularly for tiled solutions. It relieves the user of complexity in dealing with thread affinitization, offloading, memory types, and memory affinitization.
By using the hStreams library for matrix computations, developers can specify the number of streams, and various tasks can be mapped to those streams. The developer of such a code does not have to be concerned with programming tasks such as configuring OpenMP, understanding affinities, or diving deeply into the complexities of heterogeneous programming. An important aspect of using the hStreams library from Intel is that it can exploit the concurrency of data transfers from the host to the coprocessor, and can hide the latency by using multiple, asynchronous communication.
Benchmarks show that by using hStreams, an improvement of 2X can be achieved, compared to other methods. The performance of matrix multiplies and Cholesky depended on a number of parameter choices, which included the number of tiles and the number of streams used. By carefully choosing the parameters, excellent performance can be realized over a wide range of matrix sizes.
Future work using hStreams will include extending the library to include many different types of coprocessors, including future versions of the Intel Xeon Phi coprocessor. Overlapping streams need to be addressed, as well as load balancing feedback during execution.
Source: Intel, USA
Transform data into opportunity. Speed data analysis in your applications. Get Intel® DAAL

