
Rob Farber
In this special guest feature, Rob Farber from TechEnablement writes that Intel is ramping up its efforts around Machine Learning.
Intel provided a wealth of machine learning announcements following the Intel® Xeon Phi™ processor (formerly known as Knights Landing) announcement at ISC’16. Building upon the various technologies in Intel® Scalable System Framework (Intel® SSF), the machine learning community can expect up to 38% better scaling over GPU-accelerated machine learning* and an up to 50x speedup when using 128 Intel Xeon Phi nodes compared to a single Intel Xeon Phi node*. The company also announced an up to 30x improvement in inference performance* (also known as scoring or prediction) on the Intel® Xeon E5 product family due to an optimized Intel Caffe plus Intel® Math Kernel Library (Intel® MKL) package. This is particularly important as Intel notes the Intel Xeon E5 processor family is the most widely deployed processor for machine learning inference in the world.*
Reflecting Intel’s very strong commitment to open source, the CPU optimized MKL-DNN library for machine learning has been open sourced. Rounding out a cornucopia of machine learning technology announcements, the company has created a single portal for all their machine learning efforts at http://intel.com/machinelearning. Through this portal, Intel hopes to train 100,000 developers in the benefits of their machine learning technology. They are backing this up by giving early access to their machine learning technology to top research academics.
Machine and deep learning
Interest in machine learning is accelerating as commercial and scientific organizations are realizing the tremendous impact it can have across a wide range of markets ranging from Internet search, to social media, to real-time robotics, self-driving vehicles, drones and more.
Machine learning, and the more specialized deep learning approach, encompasses floating-point-, network- and data-intensive ‘training’ plus real-time, low-power inference (or ‘prediction’) operations. Training ‘complex multi-layer’ neural networks is referred to as deep-learning as these multi-layer neural architectures interpose many neural processing layers between the input data and the predicted output results – hence the use of the word deep in the deep-learning catchphrase. While the training procedure is computationally expensive, evaluating the resulting trained neural network is not.
In a nutshell, trained networks can be extremely valuable as they have the ability to very quickly perform complex, real-time and real-world pattern recognition tasks on platforms ranging from low-power devices to the most widely-deployed inference devices in the world, Intel Xeon processors. In addition, the new Intel Xeon Phi processors make an ideal multi-TF/s (Teraflop per second) training engine.
The role of Intel Scalable System Framework
Intel introduced additional details for Intel SSF to help customers purchase the right mix of validated technologies to meet their needs, including Intel HPC Orchestrator software, a family of modular Intel-licensed and supported premium products based on the publicly available OpenHPC software stack, to further reduce the burdens of HPC setup and maintenance on labs and OEMs, by providing support across the system software stack for the HPC ecosystem.
Intel Orchestrator software and the Intel Xeon Phi processor product family are but part of Intel SSF that will bring machine-learning and HPC computing into the exascale era. Intel’s vision is to help create systems that converge HPC, Big Data, machine learning, and visualization workloads within a common framework that can run in the data center – from smaller workgroup clusters to the world’s largest supercomputers – or in the cloud. Intel SSF also incorporates a host of innovative new technologies including Intel® Omni-Path Architecture (Intel® OPA), Intel® Optane™ SSDs built on 3D XPoint™ technology, and new Intel® Silicon Photonics – plus it incorporates Intel’s existing and upcoming compute and storage products, including Intel Xeon Phi processors, and Intel® Enterprise Edition for Lustre* software.
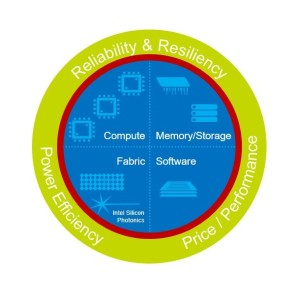
Figure 1: Intel(R) Scalable System Framework
Intel also announced the growth of the Intel SSF ecosystem to 31 partners. This group includes 19 system providers and 12 independent software vendors. Ultimately, Intel SFF will lead to a broad application catalog of tested HPC apps that the community can use with the confidence that the software will run well on a system using an Intel SSF configuration. This is one of the benefits of having validated system configurations that software developers can leverage to verify the performance of their applications. More information can be found at intel.com/ssfconfigurations.
Intel scales machine learning for deeper insight
Intel benchmarks show that a combination of Intel SSF technologies provide significantly better scaling during training than GPU-based products.*
Scaling is a fundamental to making machine learning a computationally tractable problem as even the TF/s parallelism of a single Intel Xeon or Intel Xeon Phi processor-based workstation is simply not sufficient to train in a reasonable time on many complex machine learning training sets. Time-to-model is the key metric. Instead, numerous high floating-point throughput computational nodes must be connected together via high-performance, low latency communications fabrics like Intel Omni-Path Architecture.
Apple-to-apple scaling results show that the combined advantages of Intel Xeon Phi processor floating-point capability plus the high-bandwidth, low latency advantages of Intel OPA fabric provide an up to 38% scaling advantage on GoogLeNet.
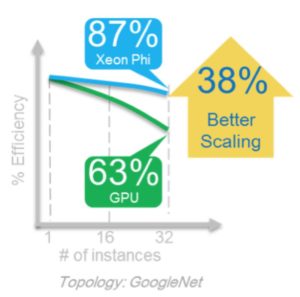
Figure 2: Scaling efficiency for an Intel SSF cluster vs. a GPU cluster
As shown in Figure 2, the efficiency of the Intel blue line remains high (87%) while the efficiency of the GPU line (shown in green) drops fairly quickly (to 63%) when evaluated from 1 to 32 nodes. The values shown reflect efficiency compared to a single node of the same type, meaning the efficiency at 32 nodes for the GPU cluster is calculated based on the single node GPU performance and similarly the 32 node Intel Xeon Phi processor efficiency is calculated based on the single Intel Xeon Phi processor performance. Results were determined by how quickly the GoogLeNet benchmark achieved a similar model accuracy (e.g. time-to-model) between the two platforms.
An up to 50x decrease in time-to-model** was achieved when scaling from 1 to 128 Intel Xeon Phi nodes when using AlexNet, another respected machine learning benchmark.

Figure 3: A 50x decrease in time-to-model compared to a single Intel Xeon Phi node *
For more information about the importance of Intel Xeon Phi to training see the first article in the Intel Machine Learning series by Rob Farber. See the second article and third articles in the series to learn more about the importance of Intel OPA an Intel Lustre for machine learning.
Intel speeds inference
The Intel announcement of an up to 30x improvement in inference performance using an Intel optimized version of Caffe and MKL compared to OpenBLAS and the default (unoptimized) Caffe. These results are based on a proof point from a proprietary customer who processes high volumes of images per second.

Figure 4: Inference speedup based on customer proof point
MKL-DNN is open source
Intel is very strongly committed to open source and to the machine learning community. Recognizing that many open-source project are highly optimized for GPUs rather that CPUs, Intel has developed and will release in 3Q16 to the open source community the MKL-DNN source code. MKL-DNN performs a number of basic and important machine learning operations that are valuable for those building and running machine learning and deep learning applications. MKL-DNN has no restrictions and is royalty-free to use.
Intel has optimized several basic machine learning operations so they run very efficiently on CPUs to complete with existing optimized GPU operations. The success of the Intel effort is clear as the DNN performance primitives demonstrate a tenfold performance increase of the Caffe framework on the AlexNet topology [1]. For example, the primitives exploit the Intel® Advanced Vector Extensions 2 (Intel® AVX2) when available on the processor and provides all building blocks essential for implementing AlexNet topology training and classification including:
- Convolution: direct batched convolution
- Pooling: maximum pooling
- Normalization: local response normalization across channels
- Activation: rectified linear neuron activation (ReLU)
- Multi-dimensional transposition (conversion)
A preview can be seen in this video, which covers the highly optimized libraries where Intel® Data Analytics Acceleration Library (Intel® DAAL) offers faster ready-to-use higher-level algorithms and Intel MKL provides lower-level primitive functions to speed data analysis and machine learning. The claim is that these libraries can be called from any big-data framework and use any communications scheme like Hadoop and MPI. Intel DAAL works hand in hand with the MKL DNN library announced at ISC’16 as it calls the MKL DNN methods.
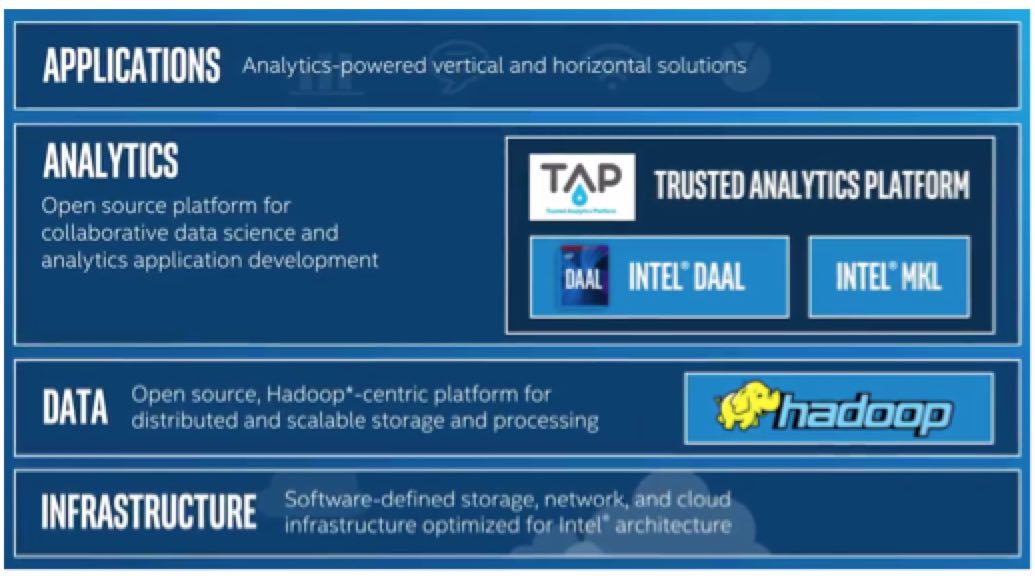
Figure 6: An important building block for machine learning and data analytic applications
Summary
Machine and deep learning neural networks can be trained to solve complex pattern recognition tasks – sometimes even better than humans. Training a machine learning algorithm to accurately solve complex problems requires large amounts of data that greatly increases the computational workload. Both TF/s Intel Xeon Phi processors and scalable distributed parallel computing using a high-performance communications fabric are an essential part of the technology that makes the training of deep learning on large complex datasets tractable in both the data center and within the cloud.
As mentioned, Intel is giving early access to their technology to top research academics. Instructions to gain access will be provided via the Intel machine learning portal.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He can be reached at info@techenablement.com.
* See Intel’s presentation for details on performance.

