Sponsored Post
This is the third in a four-part series about the Intel® Scalable System Framework. Other contributions cover Intel® Omni-Path Architecture fabric, HPC software and the OpenHPC community, and Intel® Solutions for Lustre* software.

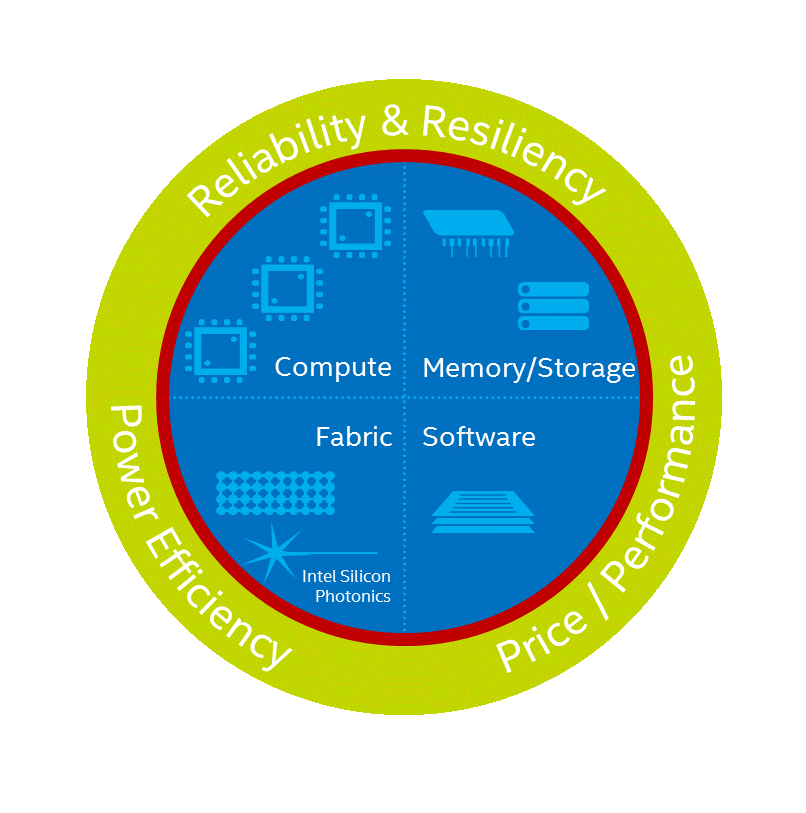
For decades, Intel has been enabling insight and discovery through its technologies and contributions to parallel computing and High Performance Computing (HPC). Central to the company’s most recent work in HPC is a new design philosophy for clusters and supercomputers called Intel® Scalable System Framework (Intel® SSF), an approach designed to enable sustained, balanced performance as the community pushes towards the Exascale era. Recently, Intel announced new additions to Intel SSF, including
• The availability of the first Intel SSF Reference Architecture with two Reference Designs, publications that will help system builders create HPC systems faster that are ready to run user workloads.
• The launch of its Intel® Xeon Phi™ processor, a high-performance, bootable host processor with many-core computing engine targeted for high performance of highly parallel workloads.
• Intel® HPC Orchestrator, a pre-integrated, pre-tested, pre-validated software stack based on OpenHPC.
The new Intel Xeon Phi processor (formerly code named Knights Landing) is designed around an integrated architecture for the powerful, highly parallel performance that is required by today’s most-demanding HPC applications, such as Machine Learning. As a bootable CPU with integrated architecture, the Intel Xeon Phi processor eliminates PCIe* bottlenecks, includes on-package memory, and directly supports Intel® Omni-Path Architecture to deliver fast, low-latency performance.
The 1st generation of the Intel Xeon Phi processor, with up to 72 out-of-order cores, Intel® Advanced Vector Extensions 512 instructions (Intel® AVX512), and up to 16GB of high-bandwidth memory, delivers 3+ TFLOPS of double-precision peak, while providing 3.5 times higher performance per watt than the previous generation, according to Intel. It can achieve up to 490 GB/s of sustained memory bandwidth without the need for additional discrete memory cards, and 100 GB/s I/O without the added cost and power needed for two fabric adapters. This level of performance will benefit many areas of HPC. Applications that will see the greatest improvements will make extensive use of the many-core architecture with ultra-wide vector capabilities. Examples of segments that will benefit from Intel Xeon Phi processor include animation, energy, finance, life sciences, manufacturing, medical, public sector, weather, and more.
The processor is built on a common x86 architecture, allowing companies to share a developer base with Intel® Xeon® processors and reuse codes across the system. Standardizing on a unified Intel® architecture enables a single programming model, thereby reducing operational and programming expenses.
As one example of the kind of performance users can expect, an evaluation of Large-Scale Atomic/Molecular Massively Parallel Simulator (LAMMPS) code was completed on a combination of Intel Xeon processor E5 v4 family and Intel Xeon Phi processor. Impressive results showed improvements in CPU+DRAM energy efficiency and simulation rates compared to non-optimized code running on previous generation processors.
Readers can find the summary tests at http://www.intel.com/content/www/us/en/high-performance-computing/hpc-xeon-phi-technology-brief.html.

