
This is the first article in a series taken from the inside HPC Guide to The Industrialization of Deep Learning.
What is Deep Learning?
 Deep learning is a method of creating artificial intelligence systems that combine computer-based multi-layer neural networks with intensive training techniques and large data sets to enable analysis and predictive decision making. A fundamental aspect of deep learning environments is that they transcend finite programmable constraints to the realm of extensible and trainable systems. Recent developments in technology and algorithms have enabled deep learning systems to not only equal but to exceed human capabilities in the pace of processing vast amounts of information.
Deep learning is a method of creating artificial intelligence systems that combine computer-based multi-layer neural networks with intensive training techniques and large data sets to enable analysis and predictive decision making. A fundamental aspect of deep learning environments is that they transcend finite programmable constraints to the realm of extensible and trainable systems. Recent developments in technology and algorithms have enabled deep learning systems to not only equal but to exceed human capabilities in the pace of processing vast amounts of information.
Why should we care?
Driven initially by internet connectivity and increasingly by a flood of internet connected devices – the ‘Internet of Things’ – we are deluged with data and overwhelmed by the inability to process it. Even though conventional computer-based systems can process data much faster than human beings, they still need to follow programmed instructions, and the pace at which we can reprogram them is still governed by human constraints. Deep learning changes that fundamentally by creating systems that can be trained autonomously, and the quality of the training becomes critical to the quality of precision and recall of the results and inferences made. Without the speed and capacity for unsupervised learning being demonstrated by deep learning systems we progressively fall behind in our ability to filter information and bring it effectively into human based decision systems. Well trained deep learning systems can fundamentally alter the economic, productivity and value propositions of business and any other kind of human interaction. We have the hardware to create the systems that are sufficiently capable, now we need to focus on how to train them rather than thinking about how to program them.
How did we get here?
The world of artificial intelligence and quasi-sentient computer systems has long been the domain of science fiction, but as direct result of available and affordable processor technology has become a much more realistic and attainable goal over the last few years. From simple origins in techniques such as regression analysis – identifying the best fit function to a scatter plot of observed data points, ever more complex pattern matching techniques have formed the foundation of machine learning which provides the basis for categorization, cognition, comprehension and conclusion that can inform a decision or action.
Machine learning evolved from the study of pattern recognition and computational learning. Using algorithms that iteratively learn from data, machine learning allows computers to find hidden insights without being explicitly programmed where to look. Deep learning extends early machine learning systems through the use of neural networks – parallel computer systems designed to mimic the functions of the mammalian brain and nervous system – which unlike conventional computer systems gain capability through training rather than being explicitly programmed.
Multi-layer neural networks process numerous input data sources through multiple ‘hidden layers’ of decision nodes that progressively filter and refine the results passed to each successive layer, ultimately providing the conclusion delivered by the final output layer.
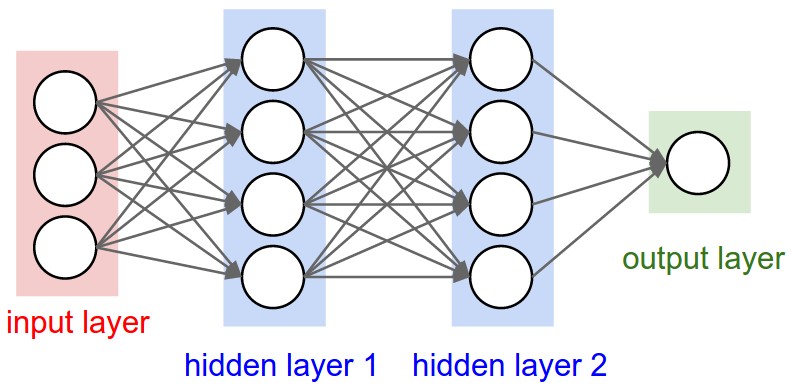
The complexity of the neural network in terms of its number of nodes and layers clearly affects the complexity of real world problems that can be addressed, but the accuracy of the delivered result is clearly the paramount consideration.
The evolution of neural networks follows the evolution of digital computers, and looking back to the 1960s, the radio or television versions of the parlor game ‘Twenty Questions’ which required people to identify an undisclosed entity by asking questions provides a good analog. Each question could only have a yes or no – a digital binary – answer, so a good starting point was frequently “Is it animal, vegetable or mineral?” The iterative result of each successive question would eventually result in an identifying question such as “Is it my manager?” It is also possible that the final and accurate result could be entirely independent of the answer to the first or any subsequent question. However a learning process that applied a significance weighting to each question and answer helped shape each subsequent question until a sufficient level of confidence was achieved to identify the unknown entity with a reasonable level of confidence.
In computer-based deep learning systems the process is not too dissimilar, except for the much larger number of nodes and layers involved. An iterative process accepts the inputs and delivers an output that is assessed for accuracy. A weighting value can then be applied or adjusted for any individual node in any given hidden layer in the neural network, the process rerun, passed through the network, assessed for changes and readjustments made iteratively to optimize the accuracy of the result. A ‘back propagation’ process is used to highlight any problems in the weighting applied to earlier layers in the decision matrix and to adjust and guide further iterations of the training regime until acceptable results are derived. This can clearly be a complex and time consuming exercise.
Building a sufficiently complex technology framework that is capable of being trained, as opposed to simply programmed, is the first critical step, followed by training with sufficient data sets to enable ‘supervised machine learning’ in a controlled environment. This involves both a training set of examples that deliver the desired outcomes combined with a larger test set of data to assess the accuracy and effectiveness of the training and application to real world situations.
More important than the infrastructure is the software toolkit that enables a deep learning or artificial intelligence system to be developed, trained and deployed in a fast and cost effective manner if deep learning is to move beyond research and non-critical hyper-scale environments to widely deployed commercial enterprise applications.
In coming weeks, this series will consist of articles that explore:
- The Industrialization of Deep Learning (this article)
- Technologies for Deep Learning
- Components for Deep Learning
- Software Framework for Deep Learning
- Examples of Deep Learning
- HPE Solutions for Deep Learning / HPE Cognitive Computing Toolkit
If you prefer you can download the complete inside HPC Guide to The Industrialization of Deep Learning courtesy of Hewlett Packard Enterprise
