In the early days of computer networking, managing everything with the CPU (onloading) was the obvious choice because it provided a general-purpose computational engine that could perform a variety of IO functions. Because the CPU did all the heaving lifting, the network cards could be designed and manufactured quickly. All that was needed was a CPU-based network “driver” program.
This the third article in a series from the insideHPC Guide to Co-Design Architectures.

insideHPC Guide to Co-Design Architectures – Download it Now
The move to network offloading is the first step in co-designed systems. As an early example, consider the ubiquitous Ethernet network that may span multiple generations. To maintain compatibility modern Ethernet still supports the original 1500 Byte packet size. A large amount of overhead is required to service the huge number of packets required for modern data rates. This amount of overhead can significantly reduce network performance. Offloading network processing (in this case interrupt coalescing) to the network interface card helped solve this bottleneck as well as some others.
Though not network related, another example of offloading is RAID storage. As is common today there are two main ways to implement RAID storage —in software, called “soft RAID,” and in hardware, called “hardware RAID.” Software RAID requires the CPU to manage the RAID array as raw disk drives. Hardware RAID presents the RAID array as a ready to use disk drive. Each approach requires a driver, however, from the CPU standpoint the hardware RAID is low overhead and often the faster solution. The same is true for network offloading.
In the past, network onloading made sense because processors continued to increase in speed. Basically it was cheaper and faster to ride on the commodity processor wave instead of developing offload devices.
No More Onload Free Lunch
The crux of the onload vs. offload design comes down to processor speed. The onload argument was based on the idea that processors continued to increase in speed and offload designs would always lag the processor. Thus, the continued increase in processor speed would make onload communication faster. In addition, the movement to multi-core meant that extra processors would be available to handle the onload overhead. Therefore, as long as core speeds and numbers of cores continued to increase so would the onload performance.
This argument made some sense until the mid- 2000’s. A graph can be created that shows the processor speeds from 1975-2015. The first thirty years (1975-2005) were what is known as the “free lunch” period where each generation of processor bumped application performance (i.e. applications got faster with each new generation without doing anything other than re-compiling). After 2005, the multicore era began and instead of processors speeds increasing, the numbers of cores in each socket began to grow. The assumption that increasing processor clock frequencies would carry onload performance forward did not hold up.
Evaluating Network Onload vs. Offload In order to test the actual performance of onload and onload approaches, the University of New Mexico and Sandia National Laboratories performed tests using a Intel TrueScale 4x QDR InfiniBand HCA (for onload) and a Mellanox ConnectX3 4X QDR InfiniBand HCA (for offload). The same hardware was used for both types of HCAs (AMD 3.8 GHz Fusion APU running Linux 2.6.32). An Intel InfiniBand Switch was used to connect the nodes. Processor frequencies were changed using dynamic voltage and frequency scaling (DVFS) 4 . Figure Two illustrates the types of results that the researchers found. The graph on the left side indicates the bandwidth vs. message size over a range of processor frequencies. The direct relation between performance and frequency can be clearly seen in the graph. The offload results on the right show much more consistent and better results.
More Cores at Lower Clock Frequencies
Another argument for continued onloading was the increasing core count for processors. The idea was to use an “extra” core for the network overhead and not impact other work on the processor (e.g. user jobs). The argument made sense because each new generation had more cores in the processor. However, there is a balance between numbers of cores, clock frequency, and heat. In general, the more cores in a processor, the slower it is clocked. Table One illustrates the evolution of the Intel Xeon E5-2690 processors over four generations.
The first four rows in Table 1 show the trend in clock speed as the number of cores is increased for the same model processor. If the number of cores is kept the same (fifth row), there is a 0.3 GHz frequency jump (2690-v1 to 2667-v4). This improvement is due to a better manufacturing process. The fastest current generation Xeon E5 is the 2637-v4 (last row) running at 3.5 GHz, but the processor only offers four cores. Thus, the addition of cores does not imply faster clock speeds and in some cases the speeds actually decrease. The prospect of using a slower “extra” core in the next generation processor may actually decrease onload network performance. And, it can get even worse. The recently released self-booting Intel Xeon Phi (stand alone Knights Landing processor) is expected to have a clock frequency in the 1-1.5 GHz range. Such a low frequency will limit how well any onload solution will work.
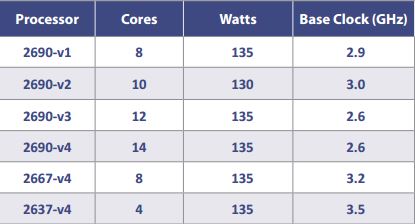
Table 1 – Cores and Clock Speeds
HPC Offloading Performance Results
The following application benchmarks indicate the advantage of offloading vs. onloading. The effect is pronounced even at a small scale (10-12 nodes). The results are for a single application running across the whole cluster. The offload improvement ranges from 35% to 70% higher for systems with InfiniBand.
For many of the tests the cluster nodes were 16-core systems connected by a Mellanox switch. Mellanox EDR InfiniBand is used for the offload tests and Intel Omni-path is used for the onload tests.
In most cases, the improvement continues as the system nodes are increased. The onload solution begins to plateau’s after six or eight nodes. In particular the LS-DYNA results show a 6-node InfiniBand cluster provides the equivalent performance a 12-node Omni-Path system.
LS-DYNA
LS-DYNA is an advanced general-purpose multiphysics simulation software package developed by the Livermore Software Technology Corporation (LSTC). The package is used for calculating complex real-world problems with a core-competency in highly nonlinear transient dynamic finite element analysis (FEA) using explicit time integration. LS-DYNA is used by the automobile, aerospace, construction, military, manufacturing, and bioengineering industries.
Quantum ESPRESSO
Quantum ESPRESSO is an integrated suite of Open Source computer codes for electronic structure calculations and materials modeling at the nanoscale level (lengths up to a few tens of nm). It is based on density functional theory, plane waves, and pseudopotentials. ESPRESSO is an acronym for opEn-Source Package for Research in Electronic Structure, Simulation, and Optimization. Quantum ESPRESSO is an open initiative, in collaboration with many groups worldwide, coordinated by the Quantum ESPRESSO Foundation.
WIEN2K
The WIEN2k package performs quantum mechanical calculations on periodic solids. WIEN2k allows users to perform electronic structure calculations of solids using density functional theory. It is an all-electron scheme including relativistic effects and has been licensed by more than 2000 user groups.
HARMONIE
Offloading is not limited to network sensitive applications. Developed by as part of High Resolution Limited Area Model (HiRLAM) program, HARMONIE is a numerical weather prediction application for short range forecasting. HARMONIE is less sensitive to network speeds than the previously mentioned applications and should work well with both onload and offload technologies.
SPEC MPI 2007 Benchmark Suite
The Standard Performance Evaluation Corporation (SPEC) is a non-profit corporation formed to establish, maintain and endorse a standardized set of relevant benchmarks that can be applied to the newest generation of high-performance computers. The offloading InfiniBand interface shows a clear advantage for all the SPEC MPI6 results . The six tests were run on 1024 total cores representing distinct and real-world application types (i.e. Ocean Modeling Weather Prediction, Computational Fluid Dynamics, DNA Matching, and Heat Transfer using Finite Element Methods).
Over the next several weeks we will explore each of these topic in detail.
- Designing Machines Around Problems: The Co-Design Push to Exascale
- The Evolution of HPC
- The First Step in Network Co-design: Offloading (this article)
- Network Co-design as a Gateway to Exascale
- Co-design for Data Analytics And Machine Learning
If you prefer you can download the insideHPC Guide to Co-Design Architectures from the insideHPC White Paper Library.

