 Today Fujitsu Laboratories announced the development of software technology that uses multiple GPUs to enable high-speed deep learning powered by the application of supercomputer software parallelization technology.
Today Fujitsu Laboratories announced the development of software technology that uses multiple GPUs to enable high-speed deep learning powered by the application of supercomputer software parallelization technology.
A conventional method to accelerate deep learning is to use multiple computers equipped with GPUs, networked and arranged in parallel. The issue with this method is that the effects of parallelization become progressively harder to obtain as the time required to share data between computers increases when more than 10 computers are used at the same time.
“Fujitsu Laboratories has newly developed parallelization technology to efficiently share data between machines, and applied it to Caffe, an open source deep learning framework widely used around the world. To confirm effectiveness with a wide range of deep learning, Fujitsu Laboratories evaluated the technology on AlexNet(1), where it was confirmed to have achieved learning speeds with 16 and 64 GPUs that are 14.7 and 27 times faster, respectively, than a single GPU. These are the world’s fastest processing speeds(2), representing an improvement in learning speeds of 46% for 16 GPUs and 71% for 64 GPUs.”
With this technology, machine learning that would have taken about a month on one computer can now be processed in about a day by running it on 64 GPUs in parallel. With this technology, research and development periods using deep learning can be shortened, enabling the development of higher-quality learning models. Fujitsu Laboratories aims to commercialize this technology as part of Fujitsu Limited’s AI technology, Human Centric AI Zinrai, as it works together with customers to put AI to use. Details of this technology were announced at SWoPP 2016 (Summer United Workshops on Parallel, Distributed and Cooperative Processing), being held from August 8 to 10 in Matsumoto, Nagano Prefecture, Japan.
Development Background
In recent years, research into an AI method called deep learning has been ongoing, and the results have been rates of image, character and sound recognition that exceed those of humans. Deep learning is a technology that has greatly improved the accuracy of recognition compared to previous technologies, but in order to achieve this it must repeatedly learn from huge volumes of data. This has meant that GPUs, which are better suited for high-speed operations than CPUs, have been widely used. However, huge amounts of time are required to learn from large volumes of data in deep learning, so deep learning software that operates multiple GPUs in parallel has begun to be developed.
Issues
Because there is an upper limit to the number of GPUs that can be installed in one computer, in order to use multiple GPUs, multiple computers have to be interconnected through a high-speed network, enabling them to share data while doing learning processing. Data sharing in deep learning parallel processing is complex, however, as shared data sizes and computation times vary, and operations are performed in order, simultaneously using the previous operating results. As a result, additional waiting time is required in communication between computers, making it difficult to achieve high-speed results, even if the number of computers is increased.

Download the insideHPC Guide to Deep Learning – Click Here
About the New Technology
By developing and applying two new technologies, Fujitsu Laboratories has achieved speed increases in learning processing. The first is a supercomputer software technology that executes communications and operations simultaneously and in parallel. The second changes processing methods according to the characteristics of the size of shared data and the sequence of deep learning processing. These two technologies limit the increase in waiting time between processing batches even with shared data of a variety of sizes.
1. Scheduling technology for data sharing
This technology automatically controls the priority order for data transmission so that data needed at the start of the next learning process is shared among the computers in advance for multiple continuous operations (Figure 1). With existing technology (Figure 1, left), because the data sharing processing of the first layer, which is necessary to begin the next learning process, is carried out last, the data sharing processing delay is even longer. With this newly developed technology (Figure 1, right), by carrying out the data sharing processing for the first layer during the data sharing processing for the second layer, the wait time until the start of the next learning process can be shortened.
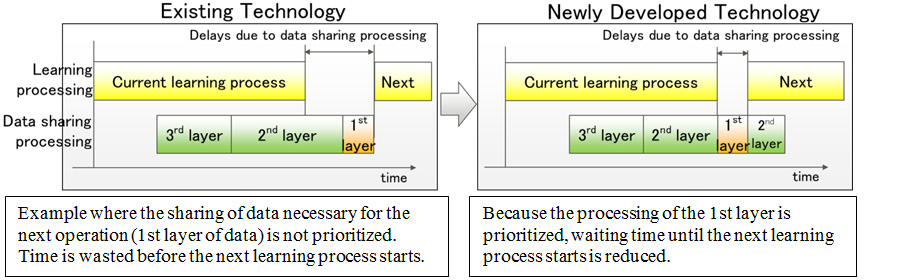
Figure 1: Scheduling technology for data sharing
2. Processing technology that optimizes operations for data size
For processing in which operation results are shared with all computers, when the original data volume is small, each computer shares data and then carries out the same operation, eliminating transmission time for the results. When the data volume is large, processing is distributed and processing results are shared with the other computers for use in the following operations. By automatically assigning the optimal operational method based on the amount of data, this technology minimizes the total operation time (Figure 2).
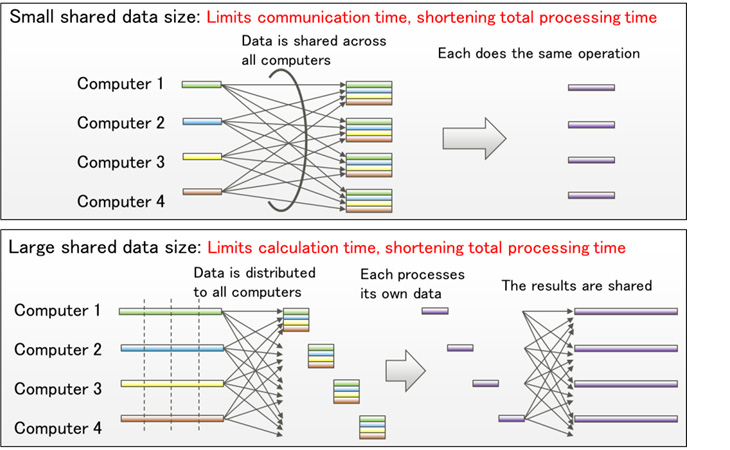
Figure 2: Differences in processing when the size of data to be shared is small (top) and large (bottom)
Effects
This newly developed technology was implemented in the Caffe deep learning framework, where, in a test measuring learning time using AlexNet on 64 GPU-equipped computers, it achieved a learning speed that is 27 times faster than a single GPU. Compared with before this technology was applied, it achieved learning speed improvements of 46% for 16 GPUs and 71% for 64 GPUs (according to internal comparisons). Using this technology, the time required for deep learning R&D can be shortened, such as in the development of unique neural network models for the autonomous control of robots, automobiles, and so forth, or for healthcare and finance, such as with pathology classification or stock price forecasting, enabling the development of higher-quality models.
Future Plans
Fujitsu Laboratories aims to commercialize this newly developed technology as part of Fujitsu’s AI technology, Human Centric AI Zinrai, during fiscal 2016. In addition, it is also working to improve the technology, in pursuit of greater learning speed.

