
 Orange Silicon Valley and CocoLink Corp have built a functional prototype of what they’re calling “the world’s highest density Deep Learning Supercomputer in a box.” Using the CoCoLink KLIMAX 210 server, they were able to load 20 overclocked GPUs in a single 4U rack unit.
Orange Silicon Valley and CocoLink Corp have built a functional prototype of what they’re calling “the world’s highest density Deep Learning Supercomputer in a box.” Using the CoCoLink KLIMAX 210 server, they were able to load 20 overclocked GPUs in a single 4U rack unit.
Editor’s Note: Satoshi Matsuoka writes that the Tsubame-KFC supercomputer actually has a higher density with with 32 Tesla K110 GPUs in 4U and that the system is used for DNN on a daily basis.
With 20 NVIDIA K40 GPUs set at overclock (GPU boost 2) mode, the system is capable of delivering a screaming 100 TeraFLOPS in a single box with 57,600 cores. With specially engineered high performance heat sinks, this pushes the limit of computational density in any server without resorting to liquid cooling.
The A.I. researchers of Orange in France were also able to use Caffe, the popular deep learning framework to test the system for scalability. They were able to scale the training job to 16 GPUs. This endeavor is continuing with various partners to adapt the framework to its full potential to exploit all the 20 GPUs in the system. The next step would be to scale to a cluster.
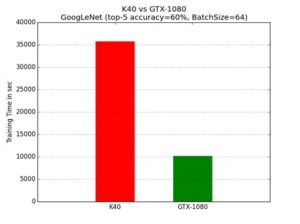
The team (Orange Silicon Valley and CoCoLink Korea) has also upgraded the system with the latest commercially available NVIDIA GPUs — GeForce GTX 1080 based on Pascal architecture. They were the first to validate a GTX 1080 for Deep Learning and identified that these consumer grade GPUs capable of achieving the same task of running GoogleNet on Caffe with 3.5 times faster speed in reaching a certain level of accuracy of image recognition during training than the NVIDIA Tesla K40 enterprise grade GPUs, which were unveiled in 2014.
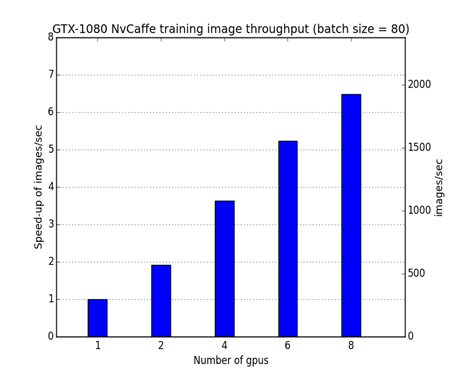
 The team was able to fire up all Pascal GPUs on overclock (Boost) mode with a theoretical aggregate computation capability of 106 TeraFLOPS (Single Precision). So far the A.I. research team of Orange France were able to scale Caffe (NVIDIA fork) to 8 GPUs with beta release of CUDA 8.0 and CuDNN 5 and CuDNN4. The eventual objective is to scale the server capability with 20 Pascal GPUs with a computational horsepower in the excess of 200+ TeraFLOPS — a feat that has never been accomplished before with consumer grade graphics card.
The team was able to fire up all Pascal GPUs on overclock (Boost) mode with a theoretical aggregate computation capability of 106 TeraFLOPS (Single Precision). So far the A.I. research team of Orange France were able to scale Caffe (NVIDIA fork) to 8 GPUs with beta release of CUDA 8.0 and CuDNN 5 and CuDNN4. The eventual objective is to scale the server capability with 20 Pascal GPUs with a computational horsepower in the excess of 200+ TeraFLOPS — a feat that has never been accomplished before with consumer grade graphics card.
 A particular training job on ImageNet data which used to take Orange researchers one and a half days (36 hours) with a single NVIDIA K40 can now be accomplished in 3.5 hours using 8 NVIDIA GTX 1080 cards. This is more than 10X increase in speed in regard to training performance.
A particular training job on ImageNet data which used to take Orange researchers one and a half days (36 hours) with a single NVIDIA K40 can now be accomplished in 3.5 hours using 8 NVIDIA GTX 1080 cards. This is more than 10X increase in speed in regard to training performance.
As the world transitions towards Exascale and A.I. turns out to be a global race, this particular experiment is a partnership between researchers of 3 countries — USA, France and South Korea — working together to accelerate Artificial Intelligence by building a supercomputer in a single server by pushing the limits of thermodynamics, geometry and price vs. performance efficiency.
Orange describes this as a research project and there are no plans at present to implement or develop this as a commercial offering. Detailed benchmark data based on this research will be published by the team in the near future as they make more progress towards optimization of the Deep Learning framework in collaboration with the open source community, academia and industry partners.
Sign up for our insideHPC Newsletter

