In this special guest feature, Rob Farber writes that Intel’s High Performance Python distribution offers a significant boost to applications performance, even without code changes.

Rob Farber
Intel recently announced the first product release of its High Performance Python distribution powered by Anaconda. The product provides a prebuilt easy-to-install Intel Architecture (IA) optimized Python for numerical and scientific computing, data analytics, HPC and more. It’s a free, drop in replacement for existing Python distributions that requires no changes to Python code. Yet benchmarks show big Intel Xeon processor performance improvements and even bigger Intel Xeon Phi processor performance improvements.
Succinctly, there are two motivations for the IA optimized Python distribution: (1) Convenience and collaboration and (2) getting near native C performance and scalability out of Python code.
Bundled Convenience and collaboration
The goal of the IA optimized Python distribution is to provide a single download so all Python programmers can gain access to native C performance and IA optimized libraries such as the Intel Data Analytics Acceleration Library (Intel DAAL) , with its new Python APIs. A broad spectrum of popular packages such NumPy, SciPy, scikit-learn are optimized with Intel Math Kernel Library (Intel MKL) and included in the distribution. Similarly, IA optimized Python compilers like Numba and Cython are provided to deliver high performance Python functions and C extensions. The idea is simple: download and go without requiring extra or piecemeal installations.
Conveniently, Python scaling issues for multi-core and many-core processors as well as distributed cluster and cloud computing environments have been addressed in many packages. Under the cover optimizations include enhanced thread scheduling through calls to the Intel Threading Building Blocks (Intel TBB) library.
Scaling across distributed systems is achieved through mpi4py and the Intel MPI library that supports both InfiniBand and the many features of the Intel Omni-Path Architecture communications fabric that decrease latency and increase scaling.
The inclusion of the Jupyter notebooks in the distribution integrates these performance and scalability optimizations into a collaborative environment designed to facilitate the coherent sharing of code, algorithms and results. For example, Jupyter documents can contain live code, equations, visualizations and explanatory text. Thus, math, code, and results live together in documents designed for collaboration, reporting and research rather than in isolation. Jupyter documents can be shared via the web, email, Dropbox, github and the Jupyter Notebook Viewer. Inclusion of Jupyter in the distribution makes it a no-brainer to try, and convenient for those who decide to use this feature. For those in a rush, click on the Jupyter web-interface to see if Jupyter is worth considering.
A two-pronged approach for production performant Python codes
Convenience and collaborative capability are the important user features, but the rubber really meets the road when the Python code moves to a production environment. Rather than wasting production cycles running inefficient code (or wasting programmer cycles recoding Python applications to run in C/C++), the IA optimized distribution takes a two pronged-approach to performant Python:
- Focus on bundling packages that call IA optimized libraries or that generate optimized vector/parallel code for IA hardware
- Make Python performance tuning a first class citizen so programmers can detect and eliminate performance bottlenecks.
The idea is to collaborate and create then run in production without having to recode or lose efficiency while providing the same profiling benefits that native code developers enjoy.
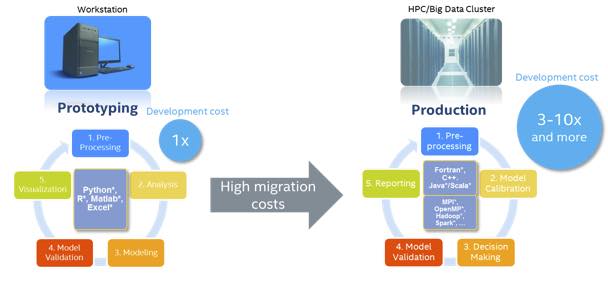
Figure 1: Eliminate migration costs with high-performance IA optimized Python (Source: Intel)
Bundled features for near native performance Python
The current Intel Python distribution bundles popular machine learning and data analytics packages that utilize optimized libraries like Intel DAAL and Intel MKL. Changes have also been made to make use of the more efficient Intel TBB threading model and IA vector and parallel capabilities.
Note: these performance optimizations are not one-off changes. To benefit the entire Python community, all optimizations are upstreamed back to the main Python trunk. Aside from the Intel Python distribution, individual optimized packages are available through conda and the Anaconda Cloud.
Production quality Python machine learning and data analytics
Machine learning is a very hot topic right now. Diane Bryant (VP and GM of the Data Center Group, Intel) expects that, “By 2020 servers will run data analytics more than any other workload”.
The push to ubiquitous machine learning in the data center likely means that more data analytic Python codes will become production jobs. Many domain scientists utilize Python, but poor performance impacts their ability to create production quality analytic solutions.
The IA optimized Python distribution is intended to change this. For example, scikit-learn is one of the more popular Python-based machine learning packages and is included in the IA optimized Python distribution. Benchmarks shows that IA optimized Python delivers significant speedups (up to nearly 8x). However, Python data analytics and machine learning packages are rapidly evolving and maturing as will be discussed next.
Intel has also included pyDAAL, a new Python version of their Data Analytics Acceleration Library, in the High Performance Python distribution. The claim is that pyDAAL optimizes the entire workflow from data acquisition to training and prediction on single nodes and in both cloud and distributed processing environments. Data layout in particular is critical to obtaining high performance on parallel devices, which is becoming ever more important as we move into the many-core era. Benchmarks show significant performance benefits (54.13x faster) compared to more generic approaches like scikit-learn.
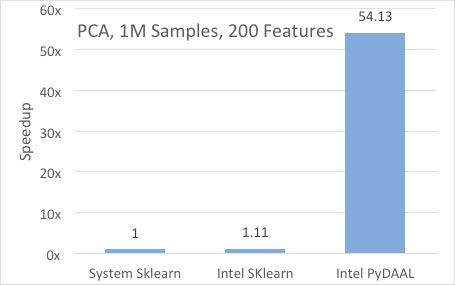
Figure 2: From data format to result, pyDAAL attempts to optimize data analytics for IA systems (Source: Intel [1])
The use of Intel TBB can really have a performance impact – especially for small and medium sized problems where inefficient thread performance cannot be hidden. With just a few annotations, array-oriented and math-heavy Python code can be JIT compiled by Numba to native machine instructions that run in parallel using Intel TBB.
The following graph shows how the Intel TBB threading model in the Intel Python distribution quickly outperforms the Fedora distributed version of Python as the problem size increases from small to large. Only for very large problem sizes are the default Python thread inefficiencies hidden.
![Figure 3: TBB threading efficiencies accelerate Python code (Source: Intel [2])](https://insidehpc.com/wp-content/uploads/2017/01/fig3.jpg)
Figure 3: TBB threading efficiencies accelerate Python code (Source: Intel [2])
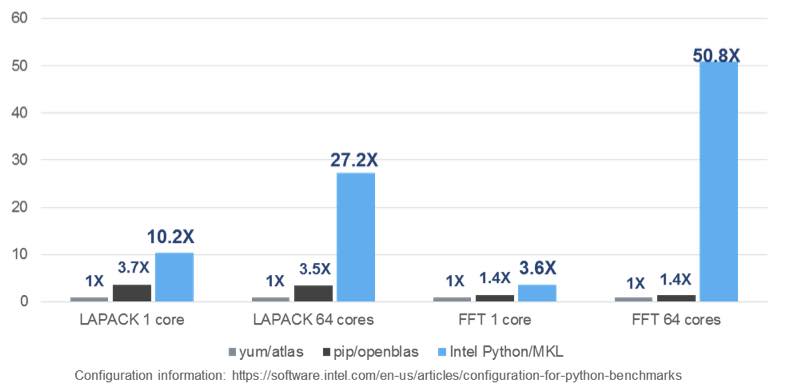
Figure 4: IA optimized performance speedups for Intel distribution of Python when running on an Intel Xeon Phi processors (Source: Intel)
Intel Math Kernel Library (Intel MKL)
Intel MKL library is also efficiently called from the IA optimized version of Python as seen in the following benchmarks using 32 Intel Xeon processor cores.
![Figure 5: Efficient MKL calls on an Intel Xeon processor (Source: Intel) [3]](https://insidehpc.com/wp-content/uploads/2017/01/fig5.jpg)
Figure 5: Efficient MKL calls on an Intel Xeon processor (Source: Intel) [3]
![Figure 6: Scalable performance demonstrated on an Intel Xeon Phi processor (Source: Intel) [3]](https://insidehpc.com/wp-content/uploads/2017/01/fig6.jpg)
Figure 6: Scalable performance demonstrated on an Intel Xeon Phi processor (Source: Intel) [3]
A distribution that makes Python performance tuning a first-class citizen
Profiling is a key step in creating high performance applications. Otherwise the programmer is blind to all but the overall application runtime and can only make educated guesses if performance can be improved along with what to try to possibly remove performance bottlenecks.
![Figure 7: A wide range of numerical domain and methods are supported (Source: Intel) [4]](https://insidehpc.com/wp-content/uploads/2017/01/fig7.jpg)
Figure 7: A wide range of numerical domain and methods are supported (Source: Intel) [4]
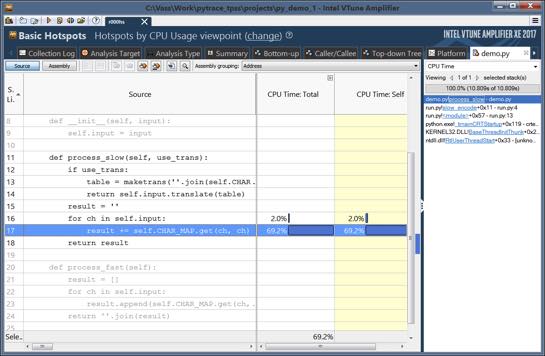
Figure 8: Intel VTune shows a performance bottleneck in Python code (Source: Intel)
Summary
This article only provided a very high-level view of the benefits of the IA optimized Python distribution. It’s easy to confirm the performance and convenience claims as the distribution can be freely downloaded from the Intel site and use it as a drop-in replacement. Use it and your Python numeric codes should simply run faster. Higher performance, along with the Jupyter collaborative notebooks means IA optimized Python has the potential to become a mainstream Python distribution. The nice thing is that everyone qualifies for the community licensing of the Intel Performance Libraries so there are no legal or cost barriers, so you can run IA optimized Python everywhere.
Performance and production users should appreciate full integration with Intel VTune profiler. See about trying Intel Parallel Studio XE before buying or determine if you qualify for a free version. The webpage notes that many students, educators, academic researchers, and open source contributors may qualify for Free Software Tools, which can include Intel Parallel Studio XE. Together, the High Performance Python distribution and Intel VTune provide a convenient and performant environment for Python code development, machine learning, and data analytics.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He can be reached at info@techenablement.com.
[1] System info: 32x Intel® Xeon® CPU E5-2698 v3 @ 2.30GHz, disabled HT, 64GB RAM; Intel® Distribution for Python* 2017 Gold; Intel® MKL 2017.0.0; Ubuntu 14.04.4 LTS; Numpy 1.11.1; scikit-learn 0.17.1.
[2] Configuration Info: – Versions: Intel(R) Distribution for Python 2.7.11 2017, Beta (Mar 04, 2016), MKL version 11.3.2 for Intel Distribution for Python 2017, Beta, Fedora* built Python*: Python 2.7.10 (default, Sep 8 2015), NumPy 1.9.2, SciPy 0.14.1, multiprocessing 0.70a1 built with gcc 5.1.1; Hardware: 96 CPUs (HT ON), 4 sockets (12 cores/socket), 1 NUMA node, Intel(R) Xeon(R) E5-4657L v2@2.40GHz, RAM 64GB, Operating System: Fedora release 23 (Twenty Three)
[3] Configuration Info: apt/atlas: installed with apt-get, Ubuntu 16.10, python 3.5.2, numpy 1.11.0, scipy 0.17.0; pip/openblas: installed with pip, Ubuntu 16.10, python 3.5.2, numpy 1.11.1, scipy 0.18.0; Intel Python: Intel Distribution for Python 2017;. Hardware: Xeon: Intel Xeon CPU E5-2698 v3 @ 2.30 GHz (2 sockets, 16 cores each, HT=off), 64 GB of RAM, 8 DIMMS of 8GB@2133MHz; Xeon Phi: Intel Intel® Xeon Phi™ CPU 7210 1.30 GHz, 96 GB of RAM, 6 DIMMS of 16GB@1200MHz
[4] Configuration info: – Versions: Intel® Distribution for Python 2017 Beta, icc 15.0; Hardware: Intel® Xeon® CPU E5-2698 v3 @ 2.30GHz (2 sockets, 16 cores each, HT=OFF), 64 GB of RAM, 8 DIMMS of 8GB@2133MHz; Operating System: Ubuntu 14.04 LTS.

