Researchers at Argonne National Laboratory are preparing to use Aurora, the laboratory’s upcoming exascale supercomputer, to delve into the inner mechanics of a variety of nuclear reactor models. These simulations promise an unprecedented level of detail, offering insights that could revolutionize reactor design by improving understanding of the intricate heat flows….
Building a Capable Computing Ecosystem for Exascale
September 18, 2023 by

With ECP, working together was a prerequisite for participation. “From the beginning, the teams had this so-called ‘shared fate,’” says Siegel. When incorporating new capabilities, applications teams had to consider relevant software tools developed by others that could help meet their performance targets, and if they didn’t choose to use them….
At the HPC User Forum: 2 Full Days in Tucson of HPC and AI
September 8, 2023 by

This week saw HPC industry analyst firm Hyperion Research host the HPC User Forum, a supercomputing conference with an end-user emphasis held four times a year (two in the U.S. and two internationally) offering two intensive days of presentations and panels involving commercial and government users, along with hardware and software vendors.
Exascale: Pagoda Updates Programming with Scalable Data Structures and Aggressively Asynchronous Communication
August 25, 2023 by
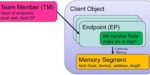
The Pagoda Project researches and develops software that programmers use to implement high-performance applications using the Partitioned Global Address Space model. The project is primarily funded by the Exascale Computing Project and interacts with partner projects….
LLNL: 9,000 Exascale Nodes for Power Grid Optimization
August 9, 2023 by
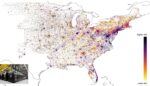
Ensuring the nation’s electrical power grid can function with limited disruptions in the event of a natural disaster, catastrophic weather or a manmade attack is a key national security challenge. Compounding the challenge of grid management is the increasing amount of renewable energy sources such as solar and wind that are continually added to the […]
ExaWorks: Tested Component for HPC Workflows
July 27, 2023 by
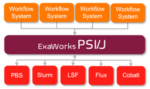
ExaWorks is an Exascale Computing Project (ECP)–funded project that provides access to hardened and tested workflow components through a software development kit (SDK). Developers use this SDK and associated APIs to build and deploy production-grade, exascale-capable workflows on US Department of Energy (DOE) and other computers. The prestigious Gordon Bell Prize competition highlighted the success of the ExaWorks SDK when the Gordewinner and two of three finalists in the 2020 Association for Computing Machinery (ACM) Gordon Bell Special Prize for High Performance Computing–Based COVID-19 Research competition leveraged ExaWorks technologies.
Exascale: Pursuing Clean Energy Catalysts with Aurora
July 13, 2023 by

Argonne National Laboratory has announced that researchers are developing exascale software tools to enable the design of new chemicals and chemical processes for clean energy production. Argonne is building one of the nation’s first exascale systems, Aurora. To prepare codes for the architecture and scale of the new supercomputer, 15 research teams are taking part […]
Introducing the HPC News Bytes Podcast, A Quick Compendium of the Latest HPC News
July 13, 2023 by

This week, @HPCpodcast introduces HPC News Bytes, a weekly program, just 3-5 minutes, a quick compendium of the most important news in HPC, AI, quantum and other advanced tech. Join us! This first episode includes: LLNL El Capitan installation commencement; LLNL Director Kim Budil named as one of the Most Creative People in Business for 2023 by Fast Company; Inflection AI’s 22,000 GPU system; New York State Department of Financial Services’ plans to buy an AI supercomputer; Intel & Nvidia collaborate on Confidential Computing….
Frontier Supercomputer Virtual Training Workshop to Be Held Aug. 23-25
July 10, 2023 by
The Oak Ridge Leadership Computing Facility (OLCF) will host a virtual Frontier Training Workshop August 23-25, 2023. This event is meant to help new Frontier users (or those intending to use Frontier) learn how to run on the system. The workshop will feature presentations and demonstrations from vendors and OLCF staff. Registration information can be […]
El Capitan Supercomputer Installation at Livermore Has Begun
July 5, 2023 by

With pictures to prove it, Lawrence Livermore National Laboratory announced today it has begun receiving and installing components for El Capitan, what is expected to be the third exascale-class supercomputer in the U.S. The laboratory shared photos on social media today. Projected to exceed 2 exaflops, El Capitan will likely be the most powerful supercomputer […]

