
In this video from the Dell EMC HPC Community meeting in Austin, Thomas Lippert from the Jülich Supercomputing Centre describes their pending 5 Petaflop Booster system. “This will be the first-ever demonstration in a production environment of the Cluster-Booster concept, pioneered in DEEP and DEEP-ER at prototype-level, and a considerable step towards the implementation of JSC’s modular supercomputing concept,” explains Prof. Thomas Lippert, Director of the Jülich Supercomputing Centre.
Taming Heterogeneity in HPC – The DEEP-ER take
August 19, 2016 by

Norbert Eicker from the Jülich Supercomputing Centre presented this talk at the SAI Computing Conference in London. “The ultimate goal is to reduce the burden on the application developers. To this end DEEP/-ER provides a well-accustomed programming environment that saves application developers from some of the tedious and often costly code modernization work. Confining this work to code-annotation as proposed by DEEP/-ER is a major advancement.”
Video: DEEP-ER Project Moves Europe Closer to Exascale
July 4, 2016 by

In this video from ISC 2016, Estela Suarez from the Jülich Supercomputing Centre provides an update on the DEEP-ER project, which is paving the way towards Exascale computing. “In the predecessor DEEP project, an innovative architecture for heterogeneous HPC systems has been developed based on the combination of a standard HPC Cluster and a tightly connected HPC Booster built of many- core processors. DEEP-ER now evolves this architecture to address two significant Exascale computing challenges: highly scalable and efficient parallel I/O and system resiliency. Co-Design is key to tackle these challenges – through thoroughly integrated development of new hardware and software components, fine-tuned with actual HPC applications in mind.”
EXTOLL Network Chip Enables Network-attached Accelerators
June 17, 2016 by

Today EXTOLL in Germany released its new TOURMALET high-performance network chip for HPC. “The key demands of HPC are high bandwidth, low latency, and high message rates. The TOURMALET PCI-Express gen3 x16 board shows an MPI latency of 850ns and a message rate of 75M messages per second. The message rate value is CPU-limited, while TOURMALET is designed for well above 100M msg/s.”
BeeGFS Parallel File System Goes Open Source
February 23, 2016 by

Today ThinkParQ announced that the complete BeeGFS parallel file system is now available as open source. Developed specifically for performance-critical environments, the BeeGFS parallel file system was developed with a strong focus on easy installation and high flexibility, including converged setups where storage servers are also used for compute jobs. By increasing the number of servers and disks in the system, performance and capacity of the file system can simply be scaled out to the desired level, seamlessly from small clusters up to enterprise-class systems with thousands of nodes.
Interview: Experimenting with DEEP-ER NAM Technology
October 18, 2014 by
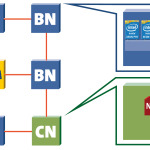
“As the name indicates: A NAM is basically a storage device plugged into the interconnect network of a Cluster. That sounds pretty simple and straightforward. But the underlying technology is quite new and exciting and the NAM concept enables entirely new approaches for using memory as a shared resource.”

