
“Linux Containers gain more and more momentum in all IT ecosystems. This talk provides an overview about what happened in the container landscape (in particular Docker) during the course of the last year and how it impacts datacenter operations, HPC and High-Performance Big Data. Furthermore Christian will give an update/extend on the ‘things to explore’ list he presented in the last Lugano workshop, applying what he learned and came across during the year 2016.”
Designing HPC, Big Data, & Deep Learning Middleware for Exascale
October 31, 2017 by

DK Panda from Ohio State University presented this talk at the HPC Advisory Council Spain Conference. “This talk will focus on challenges in designing HPC, Big Data, and Deep Learning middleware for Exascale systems with millions of processors and accelerators. For the HPC domain, we will discuss about the challenges in designing runtime environments for MPI+X (PGAS OpenSHMEM/UPC/CAF/UPC++, OpenMP, and CUDA) programming models. Features and sample performance numbers from MVAPICH2 libraries will be presented.”
Industry Analysis: AI and Deep Learning – the Voice of the Market
October 29, 2017 by

In this video, Dan Olds from OrionX presents insights from their Q2-Q3 2017 Survey on Artificial Intelligence/Machine Learning/Deep Learning – one of the industry’s most comprehensive AI/ML/DL surveys to date with more than 144 data points. “Dan Olds talks the audience through the demographics and questions, respondents’ understanding of AI/ML/DL, current projects, who is driving AI in organizations, project attributes and more.”
Video: The Era of Data-Centric Data Centers
October 28, 2017 by

Gilad Shainer gave this talk at the HPC Advisory Council Spain Conference. “The latest revolution in HPC is the move to a co-design architecture, a collaborative effort among industry, academia, and manufacturers to reach Exascale performance. By taking a holistic system-level approach to fundamental performance improvements Co-design architectures exploit system efficiency and optimizes performance by creating synergies between the hardware and the software.”
Video: HPC Meets Machine Learning
October 27, 2017 by

Andres Gómez Tato from CESGA gave this talk at the HPC Advisory Council Spain Conference. “With the explosion of Deep Learning thanks to the availability of large volume of data, computational resources are needed to train large models, using GPUs and distributed computing. When working on large models, HPC infrastructures can help to speed-up some task during the model design and training. Based on the experience at CESGA and FORTISIMO, this talk reviews the computational needs of Deep Learning, the use cases where HPC can help to Machine Learning, the performance of available Machine Learning APIs and the parallel methods commonly used during ML training.”
Driving Collaborative Research Partnerships at IBM
October 20, 2016 by

Martina Naughton presented this talk at the HPC Advisory Council Spain Conference. “IBM has a strong tradition of research collaboration with academia. We go beyond the boundaries of our IBM labs to work with colleagues in universities around the world to address global grand challenge problems. We also foster collaborative research related to transformation and innovation of businesses and governments, relationships through fellowships, grants, and funding for programs of shared interest.”
HPC: Retrospect & Looking Towards the Next 10 Years
October 17, 2016 by

In this video from the HPC Advisory Council Spain Conference, Addison Snell from Intersect360 Research looks back over the past 10 years of HPC and provides predictions for the next 10 years. Intersect360 Research just released their Worldwide HPC 2015 Total Market Model and 2016–2020 Forecast.
High Performance Interconnects: Assessment & Rankings
October 10, 2016 by

In this video from the HPC Advisory Council Spain Conference, Dan Olds from OrionX discusses the High Performance Interconnect (HPI) market landscape, plus provides ratings and rankings of HPI choices today. “In this talk, we’ll take a look at the technologies and performance of high-end networking technology and the coming battle between onloading vs. offloading interconnect architectures.”
First Look: BeeGFS File System at CSCS
October 9, 2016 by

In this video from the HPC Advisory Council Spain Conference, Hussein Harake provides an overview of the CSCS and then introduces the audience to the BeeGFS parallel file system. “BeeGFS (formerly FhGFS) is an up and coming parallel cluster file system for I/O intensive workloads. Developed with a strong focus on performance, BeeGFS was designed for very easy installation and management.”
Video: DDN Infinite Memory Engine IME
October 10, 2015 by
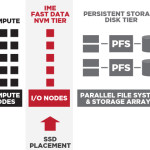
Tommaso Cecchi from DDN presented this talk at the HPCAC Spain Conference. “IME unleashes a new I/O provisioning paradigm. This breakthrough, software defined storage application introduces a whole new new tier of transparent, extendable, non-volatile memory (NVM), that provides game-changing latency reduction and greater bandwidth and IOPS performance for the next generation of performance hungry scientific, analytic and big data applications – all while offering significantly greater economic and operational efficiency than today’s traditional disk-based and all flash array storage approaches that are currently used to scale performance.”

