
In this special guest feature, Molly Presley from the Active Archive Alliance reflects on how the unstructured data storage industry has evolved and the implications for active archives. “We now have software that allows us to extract data from the archive for things like analytics, artificial intelligence, and machine learning, so it adds more value and usability to archived data. And, many of the applications and processes can now be automated through APIs and CLIs to make it easy to automate common tasks and integrate with upstream applications.”
TACC to power HSM Archives with Quantum Corp Tape Libraries
March 20, 2019 by

Today Quantum Corp. announced the Texas Advanced Computing Center has selected Quantum StorNext as their archive file system, with a Quantum Scalar i6000 tape library providing dedicated Hierarchical Storage Management. “Our ability to archive data is vital to TACC’s success, and the combination of StorNext as our archive file system managing Quantum hybrid storage, Scalar tape and our DDN primary disk will enable us to meet our commitments to the talented researchers who depend on TACC now and in the future,” said Tommy Minyard, Director of Advanced Computing at TACC.
Quantum Corporation Optimizes Data Intensive Workloads at ISC 2018
July 16, 2018 by

In this video from ISC 2018, Laura Shepard and Jason Coari from Quantum Corporation describe how the company’s high speed storage solutions power AI & HPC applications. “At ISC, Quantum highlighted end-to-end storage capabilities for large-scale HPC environments. Quantum offerings featured at their exhibit included high-performance Xcellis scale-out storage appliances to support data-intensive processing workflows, and StorNext HSM for automated migration of extremely large data sets to cost-effective storage tiers such as tape, object storage and the cloud.”
Versity names Meghan McClelland VP of Product
October 26, 2017 by

Today Versity Software announced the addition of Meghan McClelland as Vice President of Product. “ Versity is the only independent provider of advanced, scalable, high throughput software defined archiving storage technology products. Meghan shares our vision for delivering hardware agnostic, open, scalable, customer friendly large storage solutions.”
Managing Critical Data with SGI’s New Zero Watt Storage
July 14, 2016 by

Today SGI announced Zero Watt Storage, a powerful extension to its SGI DMF data management platform designed to meet growing customer demands for managing critical data. This solution was developed by SGI to offer its DMF customers fast, disk-based access to their near line data that significantly outperforms cloud storage in terms of costs and access speed up to 5X.
Video: Versity HSM – Archiving to Objects
May 8, 2016 by

In this video from the 2016 MSST Conference, Harriet Coverston from Versity presents: Versity – Archiving to Objects. “Introducing Versity Storage Manager – an enterprise-class storage virtualization and archiving system that runs on Linux. Offering comprehensive data management for tiered storage environments and the ability to preserve and protect your data forever. Maximum protection at a minimum cost. Versity supports nearly unlimited volumes of storage and offers the most robust archive policy engine on the market.”
Lustre* For the Enterprise
July 28, 2015 by

Lustre* is not just for the national labs any longer. It was born out of serving up data extremely fast to the world’s most powerful HPC clusters using parallel I/O to improve performance and scalability. Here are five reasons why Lustre is enterprise-ready.
Video: Lustre HSM in the Cloud
April 19, 2015 by

“The combination of the ephemeral nature of the cloud and directly addressable archives such as S3 suggest novel methods for using the Lustre HSM interface. Persistent data sets in the cloud need to be managed independently from an ephemeral filesystem and compute resources. Managing datasets in the cloud could, for example, involves importing data from Amazon’s S3 back into a freshly-created Lustre filesystem, performing I/O intensive computations, and then persisting the datasets back to S3 before terminating the filesystem and compute resources. Alternatives for archive formats will also be discussed. AWS S3 will be used for concrete examples, but the general methods should be applicable to other cloud environments as well.”
Video: Lustre HSM at NCI in Australia
October 10, 2014 by
In this video from the LAD’14 Conference in Reims, Daniel Rodwell from the National Computational Infrastructure (NCI) in Australia presents: Lustre HSM.
SGI Rolls Out DMF for Lustre
October 8, 2014 by
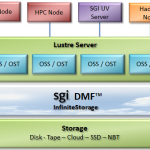
Today SGI announced the immediate availability DMF for Lustre. “With SGI DMF for Lustre, enterprises can ensure constant access to data while leveraging the significant cost benefits and scalability of tiered storage.”

