CHATSWORTH, Calif. – April 13, 2021 – DDN, the artificial intelligence (AI) and multicloud data management solutions company, today launched a certified DDN and NVIDIA set of AI solutions designed to optimize value and performance in AI integration use cases. With DDN’s A3I (Accelerated, Any-Scale AI) solutions and NVIDIA’s DGX A100 systems with NVIDIA InfiniBand and Ethernet networking, VARs and distributors “are now able […]
University of Florida, Nvidia Plan Fastest AI Supercomputer in Academia
July 22, 2020 by
The University of Florida and Nvidia have unveiled a plan to build what they say will be the world’s fastest AI supercomputer in academia, delivering 700 petaflops of AI performance and infusing AI throughout UF’s curriculum. The $70 million project will fund construction of an AI-centric supercomputing and data center and is intended to make […]
InfiniBand Powers World’s Leading Weather Forecasters’ Supercomputers
July 16, 2020 by
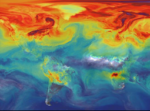
In this feature article from our friends over at Mellanox, we discuss how weather and climate models are both compute and data intensive. Forecast quality scales with modeling complexity and resolution. Resolution depends on the performance of supercomputers. And supercomputer performance depends on the underlying interconnect technology: to get higher performance, the interconnect must be able to move data quickly, effectively and in a scalable manner across compute resources.
Purdue’s ‘Anvil’ to Be Driven by Dell, AMD ‘Milan’ CPUs, Nvidia A100 Tensor Core GPUs
June 8, 2020 by

Another in a series of National Science Foundation supercomputing awards has been announced, this one a $10 million funding for a system to be housed at Purdue University to support HPC and AI workloads and scheduled to enter production next year. The system, dubbed Anvil, will be built in partnership with Dell and AMD and […]
HDR 200Gb/s InfiniBand: The Key to Success for Supercomputers Around the World
June 2, 2020 by

HDR 200Gb/s InfiniBand delivers the interconnect industry’s highest data throughput, extremely low latency and world-leading performance to HPC systems across the globe. With a foundation based on HDR 200Gb/s InfiniBand, high-performance systems are changing the way we understand the world we live in through scientific discoveries, environmental research, advanced medical research and realizing the potential for innovation in countless areas of business that are sure to drive change within the social and global landscape of tomorrow.
Agenda Posted for OpenFabrics Virtual Workshop
May 8, 2020 by

The OpenFabrics Alliance (OFA) has opened registration for its OFA Virtual Workshop, taking place June 8-12, 2020. This virtual event will provide fabric developers and users an opportunity to discuss emerging fabric technologies, collaborate on future industry requirements, and address today’s challenges. “The OpenFabrics Alliance is committed to accelerating the development of high performance fabrics. This virtual event will provide fabric developers and users an opportunity to discuss emerging fabric technologies, collaborate on future industry requirements, and address challenges.”
TYAN Launches AI-Optimized Servers Powered by NVIDIA V100S GPUs
May 7, 2020 by

Today TYAN launched their latest GPU server platforms that support the NVIDIA V100S Tensor Core and NVIDIA T4 GPUs for a wide variety of compute-intensive workloads including AI training, inference, and supercomputing applications. “An increase in the use of AI is infusing into data centers. More organizations plan to invest in AI infrastructure that supports the rapid business innovation,” said Danny Hsu, Vice President of MiTAC Computing Technology Corporation’s TYAN Business Unit. “TYAN’s GPU server platforms with NVIDIA V100S GPUs as the compute building block enables enterprise to power their AI infrastructure deployment and helps to solve the most computationally-intensive problems.”
How to Achieve High-Performance, Scalable and Distributed DNN Training on Modern HPC Systems
May 3, 2020 by

DK Panda from Ohio State University gave this talk at the Stanford HPC Conference. “This talk will focus on a range of solutions being carried out in my group to address these challenges. The solutions will include: 1) MPI-driven Deep Learning, 2) Co-designing Deep Learning Stacks with High-Performance MPI, 3) Out-of- core DNN training, and 4) Hybrid (Data and Model) parallelism. Case studies to accelerate DNN training with popular frameworks like TensorFlow, PyTorch, MXNet and Caffe on modern HPC systems will be presented.”
IBTA Updates InfiniBand Architecture Specifications for Next-Gen HPC
April 22, 2020 by

Today the InfiniBand Trade Association (IBTA) announced the public availability of the InfiniBand Architecture Specification Volume 1 Release 1.4 and Volume 2 Release 1.4. With these updates in place, the InfiniBand ecosystem will continue to grow and address the needs of the next generation of HPC, artificial AI, cloud and enterprise data center compute, and storage connectivity needs.
Update on the HPC AI Advisory Council
April 20, 2020 by

Setting the stage for the Stanford HPC Conference this week, Gilad Shainer describes how the HPC AI Advisory Council fosters innovation in the high performance computing community. “The HPC-AI Advisory Council’s mission is to bridge the gap between high-performance computing and Artificial Intelligence use and its potential, bring the beneficial capabilities of HPC and AI to new users for better research, education, innovation and product manufacturing, bring users the expertise needed to operate HPC and AI systems, provide application designers with the tools needed to enable parallel computing, and to strengthen the qualification and integration of HPC and AI system products.”

