
Left for dead last year, Intel’s Omni-Path Architecture (OPA) high performance fabric may come back to life with a Series A $20 million venture round involving Intel Capital, Downing Ventures and Chestnut Street Ventures that places OPA interconnect technology under the auspices of a spin-out start-up called Cornelis Networks. OPA was a much-promoted Intel effort […]
Omni-Path HPC Interconnect Reemerges as Intel Spin-out with $20M Investment Round from Intel Capital, Others
September 30, 2020 by
Time Lapse Video: Building the Attaway Supercomputer at Sandia
April 20, 2020 by

In this time lapse video, technicians build the new Attaway supercomputer from Penguin Computing at Sandia National Labs. In November 2019, the Attaway was #94 on the TOP500 Supercomputers list. “On February 28, 2019, Sandians lost a long-time colleague and friend, Steve Attaway. Steve spent over thirty years at Sandia, and during that time he helped bring big, seemingly impossible ideas into realization. The Attaway supercomputer is named after him.”
Podcast: Who will benefit from Intel dropping Omni-Path?
August 13, 2019 by

In this podcast, the Radio Free HPC team takes a close look at the history of High Performance Interconnects, recent news, and how the market is changing profoundly. “The departure of Intel from this segment is good news for some, and it remains to be seen what strategy Intel will adopt for the HPC market.”
NEC Delivers HPC Cluster to RWTH Aachen University in Germany
June 10, 2019 by

Today NEC announced that RWTH Aachen University in Germany has started operations of a new HPC cluster. Called CLAIX-2018 the system augments the university’s existing CLAIX-2016 installation. “RWTH Aachen is one of the most renowned universities in Germany, and this project is a lighthouse project not only for the HPC datacentre, but also for NEC,” said Yuichi Kojima, Vice President HPC EMEA at NEC Deutschland.
Thorny Flat Supercomputer comes to West Virginia University
April 3, 2019 by

Today West Virginia University announced of one of the state’s most powerful computer clusters to help power research and innovation statewide. “The Thorny Flat High Performance Computer Cluster, named after the state’s second highest peak, joins the Spruce Knob cluster as resources. With 1,000 times more computing power than a desktop computer, the Thorny Flat cluster could benefit a variety research: forest hydrology; genetic studies; forensic chemistry of firearms; modeling of solar-to-chemical energy harvesting; and design and discovery of new materials.”
Big Data over Big Distance: Zettar Moves a Petabyte over 5000 Miles in 29 Hours
October 5, 2018 by

Today AIC announced a world-record in data transfer: one petabyte in 29 hours encrypted data transfer, with data integrity checksum unconditionally enabled, over a distance of 5000 miles. The average transfer rate is 75Gbps, or 94% utilization of the available bandwidth of 80Gbps. “Even with massive amounts of data, this test confirmed once more that it’s completely feasible to carry out long distance, fully encrypted and checksum-ed data transfer at nearly the line-rate, over a shared and production network.”
Slidecast: Technology Trends Driving HPC
August 20, 2018 by

In this slidecast, Trish Damkroger from Intel presents: Technology Trends Driving HPC. “HPC is now critical for more use cases, complex workloads, and data-intensive computing than ever before. From AI and visualization to simulation and modeling, Intel provides the advantage of one platform for any workload by integrating world-class compute with powerful fabric, memory, storage, and acceleration. You can move your research and innovation forward faster to solve the world’s most complex challenges.”
Penguin Computing to Deploy Supercomputer at ICHEC in Ireland
July 18, 2018 by

Today Penguin Computing (a subsidiary of SMART Global Holdings) announced that it will deliver the new national supercomputer to the Irish Centre for High-End Computing (ICHEC) at the National University of Ireland (NUI) Galway. “With 11 supercomputers in the Top500 list and a bare-metal HPC Cloud service since 2009, we knew we could rely on Penguin Computing’s HPC expertise to address our needs in an innovative way.”
Materials Science Modeling with VASP
July 17, 2018 by
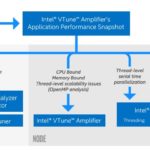
In today’s world where science and engineering depend on the simulation of new materials and their behavior is of critical importance. New materials are constantly being designed and brought into product design in order to create products that can withstand many environmental conditions and still perform for their intended use. HPC is critical for the simulation of these materials and applications which perform at the fastest speed available on a given hardware platform can lead to earlier introduction of products that contain these materials.
TIGER Supercomputer Spins Up at Princeton
July 8, 2018 by

Princeton’s new flagship TIGER supercomputer is now up and running at their High-Performance Computing Research Center (HPCRC). As a hybrid system, TIGER is built from a combination of Intel Skylake chips and NVIDIA Pascal P100 GPUs, adding up to a peak performance of 2.67 Petaflops peak performance. “Computation has become an indispensable tool in accomplishing that mission,” Dominick said. “With the newest addition to our High-Performance Computing suite, Princeton continues to equip its faculty with the most advanced computational tools available. The TIGER cluster, and the remarkable staff that support it, are symbolic of the University’s commitment to sustained excellence.”

