In this video, Wei Li, Vice President and General Manager for Machine Learning and Translation at Intel, discusses the increasing importance of AI, the vision for AI’s future benefits to humanity, and Intel’s efforts in providing an advanced platform to facilitate AI deployment from the Cloud to the edge.
Expressing Parallelism in C++ with Threading Building Blocks
September 14, 2018 by
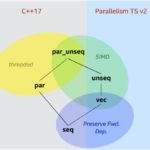
Parallelism helps applications make the best use of processors on single or multiple devices. However, parallelism implementation itself can prove a challenging task. In this video, Mike Voss, principal engineer with the Core and Visual Computing Group at Intel discusses the benefits of Intel® Threading Building Blocks (Intel® TBB), a C++ library, and how it can simplify the work of adding parallelism without the need to probe into threading details.
The Internet of Things and Tuning
September 7, 2017 by
“Understanding how the pipeline slots are being utilized can greatly increase the performance of the application. If pipeline slots are blocked for some reason, performance will suffer. Likewise, getting an understanding of the various cache misses can lead to a better organization of the data. This can increase performance while reducing latencies of memory to CPU.”
The OpenMP API Celebrates 20 Years of Success
May 25, 2017 by

OpenMP is a good example of how hardware and software vendors, researchers, and academia, volunteering to work together, can successfully design a standard that benefits the entire developer community. Today, most software vendors track OpenMP advances closely and have implemented the latest API features in their compilers and tools. With OpenMP, application portability is assured across the latest multicore systems, including Intel Xeon Phi processors.
C++ Parallel STL Introduced in Intel Parallel Studio XE 2018 Beta
May 11, 2017 by

Parallel STL now makes it possible to transform existing sequential C++ code to take advantage of the threading and vectorization capabilities of modern hardware architectures. It does this by extending the C++ Standard Template Library with an execution policy argument that specifies the degree of threading and vectorization for each algorithm used.
Intel Advisor Roofline Analysis Finds New Opportunities for Optimizing Application Performance
April 27, 2017 by
Intel Advisor, an integral part of Intel Parallel Studio XE 2017, can help identify portions of code that could be good candidates for parallelization (both vectorization and threading). It can also help determine when it might not be appropriate to parallelize a section of code, depending on the platform, processor, and configuration it’s running on. Intel Advisor Roofline Analysis reveals the gap between an application’s performance and its expected performance.
Six Steps Towards Better Performance on Intel Xeon Phi
February 16, 2017 by
“As with all new technology, developers will have to create processes in order to modernize applications to take advantage of any new feature. Rather than randomly trying to improve the performance of an application, it is wise to be very familiar with the application and use available tools to understand bottlenecks and look for areas of improvement.”
Video: Modern Code – Making the Impossible Possible
January 20, 2017 by

In this video, Rich Brueckner from insideHPC moderates a panel discussion on Code Modernization. “SC15 luminary panelists reflect on collaboration with Intel and how building on hardware and software standards facilitates performance on parallel platforms with greater ease and productivity. By sharing their experiences modernizing code we hope to shed light on what you might see from modernizing your own code.”
IA Optimized Python Rocks in Production
January 13, 2017 by

“Intel recently announced the first product release of its High Performance Python distribution powered by Anaconda. The product provides a prebuilt easy-to-install Intel Architecture (IA) optimized Python for numerical and scientific computing, data analytics, HPC and more. It’s a free, drop in replacement for existing Python distributions that requires no changes to Python code. Yet benchmarks show big Intel Xeon processor performance improvements and even bigger Intel Xeon Phi processor performance improvements.”
Video: Intel Scalable System Framework
September 14, 2016 by

Gary Paek from Intel presented this talk at the HPC User Forum in Austin. “Traditional high performance computing is hitting a performance wall. With data volumes exploding and workloads becoming increasingly complex, the need for a breakthrough in HPC performance is clear. Intel Scalable System Framework provides that breakthrough. Designed to work for small clusters to the world’s largest supercomputers, Intel SSF provides scalability and balance for both compute- and data intensive applications, as well as machine learning and visualization. The design moves everything closer to the processor to improve bandwidth, reduce latency and allow you to spend more time processing and less time waiting.”

