
Hailing from Norway, big-memory appliance maker Numascale has been a fixture at the ISC conference since the company’s formation in 2008. At ISC 2016, Numascale was noticeably absent from the show and the word on the street was that the company was retooling their NumaConnect™ technology around NVMe. To learn more, we caught up with Einar Rustad, Numascale’s CTO.
Redefining Scalable OpenMP and MPI Price-to-Performance with Numascale’s NumaConnect
September 6, 2016 by Leave a Comment

Using commodity hardware and the “plug-and-play” NumaConnect interconnect, Numascale delivers true shared memory programming and simpler administration at standard HPC cluster price points. Download this white paper to learn more.
Numascale Expands Performance and Features with NumaConnect-2
December 5, 2015 by

“At SC15, Numascale announced the availability of NumaConnect-2, a scalable cache coherent memory technology that connects servers in a single high performance shared memory image. The NumaConnect-2 advances the successful Numascale technology with a new parallel microarchitecture that results in a significantly higher interconnect bandwidth, outperforming its predecessor by a factor of up to 5x.”
1degreenorth to Prototype HPDA Infrastructure in Singapore
December 3, 2015 by
At SC15, 1degreenorth announced plans to build an on-demand High Performance Computing Big DataAnalytics (“HPC-BDA”) infrastructure the National Supercomputing Center (NSCC) Singapore. The prototype will be used for experimentation and proof-of-concept projects by the big data and data science community in Singapore.
Numascale Powers Big Data Analytics with Transtec
July 26, 2015 by

“At ISC 2015, Numascale announced record-breaking results from a shared memory system running the McCalpin STREAM Benchmark, a synthetic benchmark program that measures sustainable memory bandwidth and the corresponding computation rate for simple vector kernels. Numascale’s cache coherent shared memory system, which was targeted for big data analytics, reached 10.06 TBytes/second for the Scale function.”
Numascale Sets New World Record on STREAM Benchmark
July 13, 2015 by
Today Numascale announced record-breaking results from a shared memory system running the McCalpin STREAM Benchmark, a synthetic benchmark program that measures sustainable memory bandwidth and the corresponding computation rate for simple vector kernels.
Slidecast: Numascale Achieves Record STREAM Benchmark
July 7, 2015 by
In this slidecast, Einar Rustad from Numascale describes how the company achieved a world-record on the McCalpin STREAM benchmark using their innovative scale-out to scale-up architecture. The benchmark measures sustainable memory bandwidth and the corresponding computation rate for simple vector kernels.
AMD, Numascale, and Supermicro Deploy Large Shared Memory System
November 29, 2014 by

Numascale, in conjunction with AMD and Supermicro, has announced the successful installation of a large shared memory system at a datacentre in North America.
Numascale Teams with Supermicro & AMD for Large Shared Memory System
November 27, 2014 by
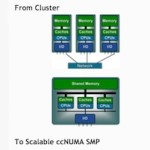
Last week at SC15, Numascale announced the successful installation of a large shared memory Numascale/Supermicro/AMD system at a customer datacenter facility in North America. The system is the first part of a large cloud computing facility for analytics and simulation of sensor data combined with historical data. “The Numascale system, installed over the last two weeks, consists of 108 Supermicro 1U servers connected in a 3D torus with NumaConnect, using three cabinets with 36 servers apiece in a 6x6x3 topology. Each server has 48 cores in three AMD Opteron 6386 CPUs and 192 GBytes memory, providing a single system image and 20.7 TBytes to all 5184 cores. The system was designed to meet user demand for “very large memory” hardware solutions running a standard single image Linux OS on commodity x86 based servers.”
Video: Numascale Big Memory Solutions from Transtec
July 11, 2014 by
In this video from ISC’14, Einar Rustad from Numascale describes the company’s innovative solution for combining multiple servers into an aggregated compute resource with extremely large memory capacity. As an HPC solution provider, Transtec delivers innovative technologies like this to customers seeking supported solutions.

