July 8, 2022 — OpenACC will hold its annual summit from Tuesday, Aug. 2 to Thursday, Aug. 4, 2022 from 7-11 am Pacific Time. It will be a digital event. The event website is here. OpenACC said this annual summit showcases leading research both accelerated by the OpenACC directives-based programming model and optimized through the […]
Are Memory Bottlenecks Limiting Your Application’s Performance?
May 23, 2019 by

Often, it’s not enough to parallelize and vectorize an application to get the best performance. You also need to take a deep dive into how the application is accessing memory to find and eliminate bottlenecks in the code that could ultimately be limiting performance. Intel Advisor, a component of both Intel Parallel Studio XE and Intel System Studio, can help you identify and diagnose memory performance issues, and suggest strategies to improve the efficiency of your code.
Making Python Fly: Accelerate Performance Without Recoding
April 19, 2019 by

Developers are increasingly besieged by the big data deluge. Intel Distribution for Python uses tried-and-true libraries like the Intel Math Kernel Library (Intel MKL)and the Intel Data Analytics Acceleration Library to make Python code scream right out of the box – no recoding required. Intel highlights some of the benefits dev teams can expect in this sponsored post.
CPU, GPU, FPGA, or DSP: Heterogeneous Computing Multiplies the Processing Power
April 1, 2019 by

Whether your code will run on industry-standard PCs or is embedded in devices for specific uses, chances are there’s more than one processor that you can utilize. Graphics processors, DSPs and other hardware accelerators often sit idle while CPUs crank away at code better served elsewhere. This sponsored post from Intel highlights the potential of Intel SDK for OpenCL Applications, which can ramp up processing power.
Achieving the Best QoE: Performance Libraries Accelerate Code Execution
March 12, 2019 by

The increasing consumerization of IT means that even staid business applications like accounting need to have the performance and ease of use of popular consumer apps. Fortunately, developers now have access to a powerful group of libraries that can instantly increase application performance – with little or no rewriting of older code. Here’s a quick rundown of Intel-provided libraries and how to get them.
Making Computer Vision Real Today – For Any Application
February 25, 2019 by

With the demand for intelligent vision solutions increasing everywhere from edge to cloud, enterprises of every type are demanding visually-enabled – and intelligent – applications. Up till now, most intelligent computer vision applications have required a wealth of machine learning, deep learning, and data science knowledge to enable simple object recognition, much less facial recognition or collision avoidance. That’s changed with the introduction of Intel’s Distribution of OpenVINO toolkit.
Data Compression Optimized with Intel® Integrated Performance Primitives
May 21, 2018 by

Intel® Integrated Performance Primitives (Intel IPP) offers the developer a highly optimized, production-ready, library for lossless data compression/decompression that targets image, signal, and data processing, and cryptography applications. The Intel IPP optimized implementations of the common data compression algorithms are “drop-in” replacements for the original compression code.
Intel MKL Compact Matrix Functions Attain Significant Speedups
February 22, 2018 by
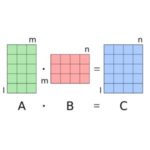
The latest version of Intel® Math Kernel Library (MKL) offers vectorized compact functions for general and specialized matrix computations of this type. These functions rely on true SIMD (single instruction, multiple data) matrix computations, and provide significant performance benefits compared to traditional techniques that exploit multithreading but rely on standard data formats.
Unlocking the Power of Parallel Coding to Access Better Performance in Multi-Core Environments
December 8, 2017 by Leave a Comment

A number of different frameworks and standards can be employed for parallel coding. The choice of the most suitable depends on the purpose of the application, its overall requirements and the target execution environment. Selecting the right framework is imperative to obtaining the best possible performance increase. The choice of framework is based on the available memory, overheads, controls and support.
Diagnose Cluster Health with Intel® Cluster Checker
October 12, 2017 by
Intel® Cluster Checker, distributed as part of Intel® Parallel Studio XE 2018 Cluster Edition, provides a set of system diagnostics and analysis methods in a single tool to assist managing clusters of any size. “Think of Intel Cluster Checker as a clinical system that detects signs that issues affecting the health of the cluster exist, diagnoses those issues, and suggests remedies. Using common diagnostic tools signs that may indicate symptoms leading to a diagnosis and a possible solution.”

