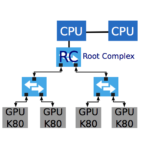
“MeteoSwiss, the Swiss national weather forecast institute, has selected densely populated accelerator servers as their primary system to compute weather forecast simulation. Servers with multiple accelerator devices that are primarily connected by a PCI-Express (PCIe) network achieve a significantly higher energy efficiency. Memory transfers between accelerators in such a system are subjected to PCIe arbitration policies. In this paper, we study the impact of PCIe topology and develop a congestion-aware performance model for PCIe communication. We present an algorithm for computing congestion factors of every communication in a congestion graph that characterizes the dynamic usage of network resources by an application.”
A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers
April 14, 2017 by
GPUs and Flash in Radar Simulation and Anti-Submarine Warfare Applications
February 21, 2017 by

In this week’s Sponsored Post, Katie Garrison, of One Stop Systems explains how GPUs and Flash solutions are used in radar simulation and anti-submarine warfare applications. “High-performance compute and flash solutions are not just used in the lab anymore. Government agencies, particularly the military, are using GPUs and flash for complex applications such as radar simulation, anti-submarine warfare and other areas of defense that require intensive parallel processing and large amounts of data recording.”
Video: One Stop Systems Takes GPU Density to the Next Level at SC16
November 22, 2016 by

In this video from SC16, Nate Parada from One Stop Systems describes the company’s new High Density Compute Accelerator (HDCA) for Deep Learning. “The CA16000 High Density Compute Accelerator with sixteen NVIDIA Tesla GPU accelerators is used for a variety of HPC applications including oil and gas exploration and financial services. Completely integrated with the GPUs most suited for a specific application, it’s easy installation and tested reliability makes it superior to alternative products.”
Creating Balance in HPC on the Piz Daint Supercomputer
August 11, 2016 by

The flagship supercomputer at the Swiss National Supercomputing Centre (CSCS), Piz Daint, named after a mountain in the Alps, currently delivers 7.8 petaflops of compute performance, or 7.8 quadrillion mathematical calculations per second. A recently announced upgrade will double its peak performance, thanks to a refresh using the latest Intel Xeon CPUs and 4,500 Nvidia Tesla P100 GPUs.
Video: HPE Apollo 6500 Takes GPU Density to the Next Level
July 20, 2016 by

In this video from ISC 2016, Greg Schmidt from Hewlett Packard Enterprise describes the new Apollo 6500 server. With up to eight high performance NVIDIA GPUs designed for maximum transfer bandwidth, the HPE Apollo 6500 is purpose-built for HPC and deep learning applications. Its high ratio of GPUs to CPUs, dense 4U form factor and efficient design enable organizations to run deep learning recommendation algorithms faster and more efficiently, significantly reducing model training time and accelerating the delivery of real-time results, all while controlling costs.
GPU-Powered Systems Take Top Spot & Set Performance Records at ASC16
May 1, 2016 by

Over at the Nvidia Blog, George Millington writes that, the fourth consecutive year, the Nvidia Tesla Accelerated Computing Platform helped set new milestones in the Asia Student Supercomputer Challenge, the world’s largest supercomputer competition.
How HPE Makes GPUs Easier to Program for Data Scientists
April 21, 2016 by

In this video from the 2016 GPU Technology Conference, Rich Friedrich from Hewlett Packard Enterprise describes how the company makes it easier for Data Scientists to program GPUs. “In April, HPE announced a public, open-source version of the platform called the Cognitive Computing Toolkit. Instead of relying on the traditional CPUs that power most computers, the Toolkit runs on graphics processing units (GPUs), inexpensive chips designed for video game applications.”
Supermicro Showcases New GPU SuperServer at GTC 2016
April 12, 2016 by

In this video from the 2016 GPU Technology Conference, Jason Pai from Supermicro describes the new 1028GQ-TRT SuperServer. With support for up to four Nvidia Tesla K80 GPUs, the 1U superserver offers extreme compute density in 1U of rack space. “From HPC to Deep Learning and Big Data Analytics, denser, more powerful GPU solutions have become a necessity in order to service the next generation of GPU-accelerated applications. At GTC, Supermicro demonstrated how these applications have progressed, and how its GPU solutions are influencing this evolution.”
TYAN to Showcase 4U, 4x GPU Platform at GTC 2016
April 1, 2016 by

The FT76-B7922 is the first multi-purpose server platform that simultaneously supports scale-up (fat node) and scale-out (many-core CPU node). With 1:1 CPU to GPU ratio, TYAN’s FT76-B7922 provides a high price/performance and performance/watt for HPC community that both needs CPU and GPU intensive computing workloads” said Albert Mu, Vice President of MITAC Computing Technology Corporation’s TYAN Business Unit.
IBM Watson CTO Rob High to Keynote GPU Technology Conference
March 10, 2016 by

Today Nvidia announced that Rob High, IBM Fellow, VP and chief technology officer for Watson, will deliver a keynote at our GPU Technology Conference on April 6. High will describe the key role GPUs will play in creating systems that understand data in human-like ways. “Late last year, IBM announced that its Watson cognitive computing platform has added NVIDIA Tesla K80 GPU accelerators. As part of the platform, GPUs enhance Watson’s natural language processing capabilities and other key applications.”

