 Since the first day that NVIDIA spotted a few researchers using its cards for computation, not graphics, and decided to get into the computing business the company has been focused on building an entire ecosystem around its product. Unlike accelerator vendor ClearSpeed (the darling of SC several years ago), NVIDIA was able to leverage mass market economics (inexpensive-ish hardware) alongside a community of partners enabled by its own investments in programming interfaces, documentation, and “community” to turn good hardware into a phenomenon. It is now enjoying the fruits of those investments and riding a network effect into even deeper penetration in the HPC market. Today the company estimates that there are over 200,000 CUDA developers world wide. While its not clear that NVIDIA’s accelerator hegemony will last forever — both Intel and AMD are pursuing plans to include accelerators into their base silicon — the company is in an outstanding position in the near term.
Since the first day that NVIDIA spotted a few researchers using its cards for computation, not graphics, and decided to get into the computing business the company has been focused on building an entire ecosystem around its product. Unlike accelerator vendor ClearSpeed (the darling of SC several years ago), NVIDIA was able to leverage mass market economics (inexpensive-ish hardware) alongside a community of partners enabled by its own investments in programming interfaces, documentation, and “community” to turn good hardware into a phenomenon. It is now enjoying the fruits of those investments and riding a network effect into even deeper penetration in the HPC market. Today the company estimates that there are over 200,000 CUDA developers world wide. While its not clear that NVIDIA’s accelerator hegemony will last forever — both Intel and AMD are pursuing plans to include accelerators into their base silicon — the company is in an outstanding position in the near term.
 And more evidence of that came this week as IBM announced that it had integrated both NVIDIA’s current and last generation GPU technology into its scale-out iDataPlex server line. The configuration puts 2 CPUs in a node plus 2 GPUs, either the M2050 Fermi technology or the last generation M1060. The “M” series are shipped without heatsinks and are designed to be embedded into servers that will handle the cooling. Other vendors are working with NVIDIA, of course, including Appro and SuperMicro. But in the top-tier HPC vendors much of those efforts are in low-end systems like the Octane III from SGI or Cray’s CX-1. HP is said to be working with customers on custom builds that include GPUs, but it isn’t talking about that work publicly.
And more evidence of that came this week as IBM announced that it had integrated both NVIDIA’s current and last generation GPU technology into its scale-out iDataPlex server line. The configuration puts 2 CPUs in a node plus 2 GPUs, either the M2050 Fermi technology or the last generation M1060. The “M” series are shipped without heatsinks and are designed to be embedded into servers that will handle the cooling. Other vendors are working with NVIDIA, of course, including Appro and SuperMicro. But in the top-tier HPC vendors much of those efforts are in low-end systems like the Octane III from SGI or Cray’s CX-1. HP is said to be working with customers on custom builds that include GPUs, but it isn’t talking about that work publicly.
The move by IBM quadruples the peak FLOPS customers can stuff into a rack to 49 TFLOPS (double precision FLOPS using the M2050 “Fermi” technology), even though the number of Intel Westmere-powered nodes in that rack falls from 84 to 42 to accommodate the GPUs. Potential customers should also be aware that the power per rack also increases slightly, from 27.55 kW to 31kW, but this is not bad at all when you look at the change in FLOPS/kW: from .42 TFLOPS/kW without GPUs to 1.6 TFLOPS/kW with GPUs. Of course, all FLOPS are not created equally, and the the GPU-enabled comparison most of the performance comes from the GPUS — 43.3 TFLOPS from the GPUs versus 5.9 from the Westmeres. If your application isn’t well-suited to GPUs you obviously won’t see much benefit from all those added FLOPS. You can learn more about the new iDataPlex option in this video from IBM at YouTube.
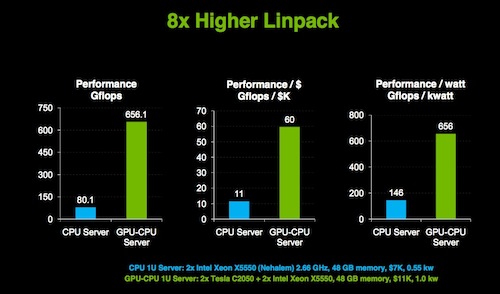
NVIDIA’s Sumit Gupta briefed me earlier this week on the announcement, and he took the opportunity share some performance results. The graph below compares the performance of a 1U, 2 socket, 2.66 GHz Nehalem server with 48 GB of memory to that same server plus 2 Tesla C2050 Fermis. On the HPL at least the difference is an 8x improvement. Gupta also walked me through an example he had built to show that $1M gets you about 10 TFLOPS in a CPU-only IB-based cluster, and 50 TFLOPS if you are able to do most of your computation courtesy of GPUs.
To demonstrate the size of its reach into the research application space, NVIDIA examined the major codes in use by the Barcelona Supercomputing Center, and found that of the 11 applications that make up the majority of that center’s work, 5 already have CUDA ports (NAMD, AMBER, GADGET, GROMACS, and CHROMA), and 4 have viable alternatives that are ported to CUDA (ABINIT, TeraChem, PHMC, and CDOCK). Notice that there is a lot of molecular dynamics there, and NVIDIA is clearly picking an example center that is dominated by applications its does especially well on, but I don’t think this changes the value of the message. If you fall into a certain class of applications then not only might GPUs be a good option for you, but the application work may already be done.
There is one item of interest that NVIDIA wasn’t talking about this week, though: the ORNL system. A deal was implied during the Fermi launch in the fall of last year through which ORNL would build an ORNL-scale super using NVIDIA’s GPUs, but so far neither side has been willing to spill the beans on any details.


[…] Nvidia’s Telsa 20-series GPUs in the new version of its iDataPlex HPC server. InsideHPC, IBM adoption moves NVIDIA into the big leagues (20 May […]