 This morning Intel and the U.S. Department of Energy announced a $200 million supercomputing investment coming to Argonne National Laboratory. As the third of three Coral supercomputer procurements, the deal will comprise an 8.5 Petaflop “Theta” system based on Knights Landing in 2016 and a much larger 180 Petaflop “Aurora” supercomputer in 2018. Intel will be the prime contractor on the deal, with sub-contractor Cray building the actual supercomputers.
This morning Intel and the U.S. Department of Energy announced a $200 million supercomputing investment coming to Argonne National Laboratory. As the third of three Coral supercomputer procurements, the deal will comprise an 8.5 Petaflop “Theta” system based on Knights Landing in 2016 and a much larger 180 Petaflop “Aurora” supercomputer in 2018. Intel will be the prime contractor on the deal, with sub-contractor Cray building the actual supercomputers.
DOE Under Secretary for Science and Energy Lynn Orr announced the deal, saying that $200 million supercomputing investment will help advance U.S. leadership in scientific research, maintain the nation’s position at the forefront of next-generation exascale computing, and ensure America’s economic and national security.
Why is Intel the Prime Contractor?
While we’ve seen a lot of speculation about why Intel might be resurrecting their Paragon HPC division from the 1990s, the reason the company went after Coral as the Prime is not mysterious at all — only chip vendors were allowed to bid on Coral and Intel wanted the business.
As reported here, IBM (with Nvidia and Mellanox) won the first two Coral supercomputer deals that were announced last year, and the Coral contracts specified that all three systems could not be the same architecture. So the good money was on Intel all along for this third and final Coral deal at Argonne.
The Dawn of Intel Scalable System Framework
That Intel went in with Cray as a subcontractor is also no surprise, as Intel the company has a solid record of delivering efficient extreme scale supercomputers based on Intel processors with their Cray XC (Cascade) platform. Intel also has a lot of Cray DNA on board after buying the company’s Aries interconnect technology and engineering staff back in 2012. Aries will be the interconnect for the Theta Cray XC system at Argonne.
In a way, this Argonne announcement is a culmination of calculated moves by Intel over the past three or four years. Besides buying the Cray Aries technology, they also picked up the True Scale InfiniBand business from QLogic in 2012. Intel’s continued engineering on True Scale morphed into their Omni Path technology, which will figure prominently in the Aurora system at Argonne in 2018.
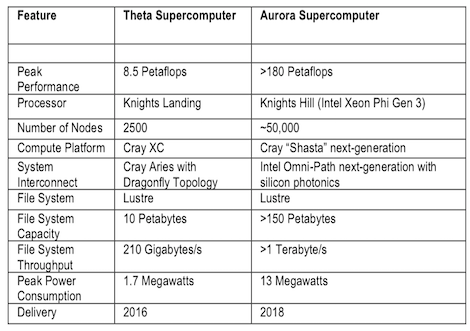
Of course, extreme scale supercomputers need huge IO bandwidth and high performance storage. Enter Lustre, which will power both Argonne systems with a 10 Petabyte file system for Theta and a whopping 150 Petabytes at 1 Terabyte/sec for Aurora. Can Intel deliver? Absolutely–the company’s 2012 acquisition of Whamcloud has brought on board world-class engineering talent in parallel file systems.
What we’re seeing here today is the Dawn of Intel Scalable System Framework. It’s not a marketing name, but it is a solid foundation for building Aurora and the Exascale systems that will follow in the coming decade.
 What We Know About Aurora
What We Know About Aurora
As we said earlier, Aurora is set for deliver in 2018 and will be powered by third generation Intel Xeon Phi (code named Intel Knights Hill) and integrated into Cray’s next generation Shasta platform. While its peak performance of 180 Petaflops may look like an off-the-cuff calculation, the machine should actually able to deliver real application performance with its massive 24 Terabytes/sec of bisection bandwidth.
The 13 Megawatt system will be extremely energy efficient as well, with something like 13 Gigaflops/watt. As a testament to the staying power of Moore’s Law, Aurora will be 18x more powerful than its predecessor at Argonne, Mira, a Blue Gene/Q system, while only requiring 2.7 times the energy usage.
The Aurora supercomputer represents a new architectural direction based on Intel’s HPC scalable system framework. The framework is a flexible blueprint for developing high-performance, balanced, power-efficient and reliable systems capable of supporting both compute- and data-intensive workloads. The framework combines next-generation Intel Xeon and Xeon Phi processors, Intel Omni-Path Fabric, innovative memory technologies, Intel Silicon Photonics Technology and the Intel Lustre parallel file system – with the ability to efficiently integrate these components into a broad spectrum of HPC system solutions. The framework also provides a ubiquitous and standards-based programming model, extending the ecosystem’s current investments in existing code for future generations.


Very interesting numbers comparing Theta to Aurora:
Theta: Knights Landing, 2,500 nodes, 8.5 PFlops, 1.7 MWatts
Aurora: Knights Hill, 50,000 nodes, 180 PFlops, 13 MWatts
Node count increases by 20X, performance increases by 21X, so no particular performance advantage shown for KNH over KNL, but power increases by only 7.6X, so almost 3X more power efficient.
almost $1 miillion per peta. so price went down to 1/20th.