
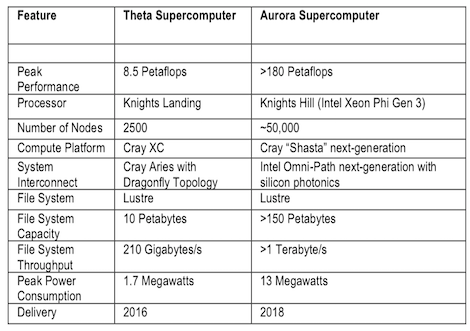
 As reported here, the DOE recently announced a $200 million supercomputing investment coming to Argonne National Laboratory. As the third of three Coral supercomputer procurements, the deal will comprise an 8.5 Petaflop “Theta” system based on Knights Landing in 2016 and a much larger 180 Petaflop “Aurora” supercomputer in 2018. Intel will be the prime contractor on the deal, with sub-contractor Cray building the actual supercomputers.
As reported here, the DOE recently announced a $200 million supercomputing investment coming to Argonne National Laboratory. As the third of three Coral supercomputer procurements, the deal will comprise an 8.5 Petaflop “Theta” system based on Knights Landing in 2016 and a much larger 180 Petaflop “Aurora” supercomputer in 2018. Intel will be the prime contractor on the deal, with sub-contractor Cray building the actual supercomputers.
To learn more, we caught up with Alan Gara, principal architect of the Aurora system. What follows is a condensed version of that discussion.
insideHPC: Were you involved with the design and development of the Theta system also, or were you mostly focused on Aurora?

Alan Gara, Intel
Alan Gara: I was focused largely on the Aurora system. Theta as you know is very close to a Cray product that they are delivering, and is similar in performance to what Argonne has currently. Theta will give Argonne a platform for which they can migrate their codes before the arrival of Aurora.
insideHPC: Will the Aurora system be based on the Intel Omni-Path interconnect?
Alan Gara: Yes you have that right. The Aurora system is based on our Omni-Path second generation. This is an Intel interconnect that we’ve been developing for some time now, and we’re really excited about the capabilities that we expect and scalability that we expect it to bring to high performance computing.
insideHPC: Since the announcement just happened, they weren’t able to provide any drawings of any architecture. How does the burst buffer talk to the rest of the system? Is it the Omni-Path?
 Alan Gara: Yes. So the compute nodes connect up through a switch. So first, let me try and draw you a mental picture if I could. I apologize that you don’t have a diagram sitting in front of you, but think of the compute nodes all interconnected with a switchless fabric. So think of racks that are connected to racks and all the switching capabilities all built into those racks. There’s no hierarchy of switches outside the racks. So that forms what you might think of as sort of the compute cluster. And this is what you would typically run your MPI traffic over in your processor-to-processor communication. Out of each of those racks (and actually in a very fine-grained sense, out of every one of these groups of nodes in the racks) we bring out another Omni-Path 2 Link to an external Omni-Path switch which is then going to be used for the IO system. Those switches allow you to connect up to burst buffers.
Alan Gara: Yes. So the compute nodes connect up through a switch. So first, let me try and draw you a mental picture if I could. I apologize that you don’t have a diagram sitting in front of you, but think of the compute nodes all interconnected with a switchless fabric. So think of racks that are connected to racks and all the switching capabilities all built into those racks. There’s no hierarchy of switches outside the racks. So that forms what you might think of as sort of the compute cluster. And this is what you would typically run your MPI traffic over in your processor-to-processor communication. Out of each of those racks (and actually in a very fine-grained sense, out of every one of these groups of nodes in the racks) we bring out another Omni-Path 2 Link to an external Omni-Path switch which is then going to be used for the IO system. Those switches allow you to connect up to burst buffers.
The burst buffers are a set of Xeon-based nodes talking Omni-Path as well, and those have solid state memory in them that we use to allow us to really absorb high bandwidth I/O and sort of alleviate some of the pressure that traditional spinning disc type file systems suffer from these days. As we scale compute, discs are not scaling in performance the way compute systems are scaling. It presented a bandwidth mismatch and so this is the way we addressed that.
In this video, Intel Fellow Al Gara talks about new architectural directions and the power of integration.
insideHPC: So Alan, how would you describe the topology? Is it a Dragonfly?
Alan Gara: Yes. What I described as the rack topology is a Dragonfly. It sort of follows the topology that Cray has already pioneered with the Aries interconnect, and so it’s similar to that. However, because it’s based on Omni-Path solutions from Intel, there are new capabilities that we put into some of the switching fabric that it rides on to really drive efficiency. So it’s a combination of hardware and software to really get us the performance of the Dragonfly. Dragonfly is just the description of the topology. But then there’s lots of devils in the details type of things that are under the covers to ensure efficiency for many different types of communication patterns – whether it’s local nearest neighbor or whether it’s global things like you would do in an FFT or transpose – we can do all of those things very well and deal with all the congestion and conflicts in the most optimal way the topology allows.
 insideHPC: So Alan, you were the architect for the Blue Gene/Q supercomputers. How was that experience helpful in understanding the requirements to help Argonne with the transition?
insideHPC: So Alan, you were the architect for the Blue Gene/Q supercomputers. How was that experience helpful in understanding the requirements to help Argonne with the transition?
Alan Gara: Well, I think it helps in a number of ways. Of course, I was also the lead architect for the system that’s now Mira, and so I’m of course familiar both with the research staff here at Argonne as well as how the machine is being used and their requirements that their users bring. And so one of the things that we made sure that we got – and I think is going to map exceptionally well – is to really have a path from their current users to move on to both Theta and Aurora. I think that this is going to be a really good story for them because of the accountability between the two systems from a program model perspective. From a performance capability and scalability perspective, I think this is going to be a good story.
 insideHPC: I don’t know if you can comment on the other Coral systems and the task that’s in front of them as far as porting codes. Would you say the leap for their codes is going to be harder that what Argonne is facing, or are both challenging?
insideHPC: I don’t know if you can comment on the other Coral systems and the task that’s in front of them as far as porting codes. Would you say the leap for their codes is going to be harder that what Argonne is facing, or are both challenging?
Alan Gara: Well, I don’t think there’s one answer to that question. I think that again, they have some codes that were already ported to GP-GPUs. So from that perspective, some of that shouldn’t be moving heaven and earth, but there’s no question that moving to a different program environment is a heavy lift, and that’s why we’ve tried to avoid that in this case. And so that’s why we’re really trying to take a very straight forward approach in terms of how we would be able to migrate and really maintain the investment that the Department of Energy, and Argonne in particular, and their users have put into getting things to run efficiently on the Mira Blue Gene/Q.
insideHPC: Alan, I know you’re busy so I just want to do a quick wrap up question here. You’ve architected the system. You’ve got the contract signed. Is the hard work just begun?
Alan Gara: Yeah, it is [chuckles] just starting. We’ve of course – with the time scales that we’re talking about – we’re well on our way in terms of the development of a lot of these components and ingredients that are going to go into the system. So it’s not like we’re just starting now. We’ve been running with this for quite a while, already years in terms of the development of this, but it gets harder as we go forward as we certainly don’t have any silicon to bring up yet. There’s a lot of fun and hard work ahead, but we’re looking forward to it, and it’s a very exciting time here at Intel.

