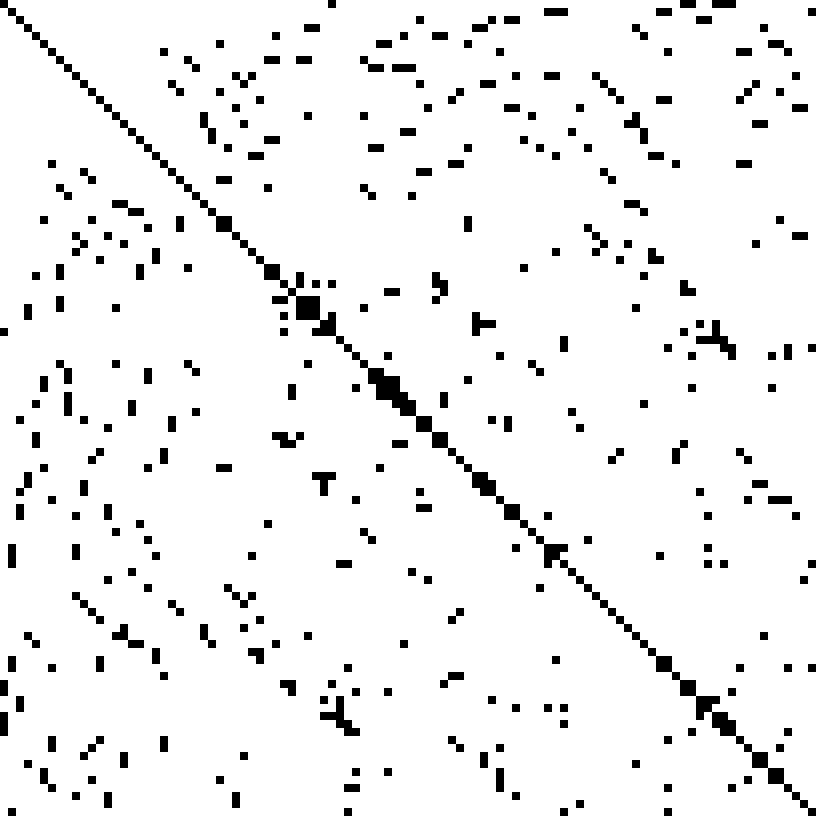
 Sparse matrix computations are prevalent in many scientific and technical applications. In many simulation applications, the solving of the sparse matrix-vector multiplication (SpMV) is critical for high performing computing. A sparse matrix contains a high percentage of zero’s, (as compared to dense matrices) and to obtain high end performance, special data structures are needed as well as logic to avoid meaningless multiplies which contain a zero.
Sparse matrix computations are prevalent in many scientific and technical applications. In many simulation applications, the solving of the sparse matrix-vector multiplication (SpMV) is critical for high performing computing. A sparse matrix contains a high percentage of zero’s, (as compared to dense matrices) and to obtain high end performance, special data structures are needed as well as logic to avoid meaningless multiplies which contain a zero.
While vectorization units are increasing in width, the effective bandwidth per core is decreasing. For sparse calculations, these two trends conflict, so an innovative approach is needed to obtain high performance using the Intel Xeon Phi coprocessor. First, the data can be stored such that zeros are eliminated, and blocking can be used to optimize the data transfer bottleneck.
A parallel implementation of SpMV can be implemented, using OpenMP directives. However, by allocating memory for each core, data races can be eliminated and data locality can be exploited, leading to higher performance. Besides running on the main CPU, vectorization can be implemented on the Intel Xeon Phi coprocessor. By blocking the data in various chunks, various implementations on the Intel Xeon Phi coprocessor can be run and evaluated.
Various test cases (size and sparseness of the matrix) were run using the Intel XeonPhi 7120A coprocessor. Consistently, across the various test cases, by using a partially distributed method, the Intel Xeon Phi coprocessor showed excellent performance typically when using an 8 x 1 block size.
Source: KU Leuven, Belgium
C – Big Results
Turn Big Research into Big Results
Accelerate data analysis with Intel® Parallel Studio XE.
Try it >


Is there a link to the original source?
This post is derived from the Chapter 27 of the book “High Performance Parallelism Pearls Volume One: Multicore and Many-core Programming Approaches” http://www.amazon.com/High-Performance-Parallelism-Pearls-Volume/dp/0128021187.