
In this special guest feature, Gilad Shainer from Mellanox writes that the network is the key to future scalable systems.
HPC Frequently Reinvents Itself to Keep Pace

Gilad Shainer, VP of Marketing, Mellanox
In the world of high-performance computing, there is a constant and ever-growing demand for even higher performance. Technology providers have worked ceaselessly to keep up with that demand, with each new generation of faster, more reliable, and more efficient systems.
Ultimately, though, every technology reaches its limits, and progress can therefore stall unless there is a paradigm shift that changes the playing field. In the past 20 years, we have witnessed a 1,000,000X performance increase in high-performance computing systems, and three major shifts in the underlying technology that enables these systems.
The first major change occurred when the industry moved from symmetric multiprocessing (SMP) architecture to clusters. This move took advantage of high speed networking to build cost effective clusters by utilizing off-the-shelf components that can scale as needed and deliver a more cost-effective structure.
The second shift occurred when it was no longer feasible to improve performance by increasing the CPU frequency. This led to a move from single core to multi-core processors, which multiplied the performance but which required scalable interconnect to handle so many more processors per server.
Today, we face a new performance bottleneck, as a CPU-only design cannot scale further in terms of performance. As the industry looks to move away from a CPU-centric architecture, the network becomes an integral part of the equation. By creating synergies between the software and the hardware, Co-Design architecture is the latest and third paradigm shift for the high-performance computing industry.
The Latest Revolution in HPC
Co-Design is a collaborative effort among industry thought leaders, academia, and manufacturers to reach Exascale performance by taking a holistic system-level approach to fundamental performance improvements. Co-Design architecture enables all active system devices to become acceleration devices by orchestrating a more effective mapping of communication between devices in the system. This produces a well-balanced architecture across the various compute elements, networking, and data storage infrastructures that exploits system efficiency.
By treating the network as a co-processor, tasks can be offloaded from the CPU, allowing it to concentrate on the jobs it is meant to handle. An intelligent network can also perform tasks that the CPU cannot effectively manage, such as data aggregation protocols.
Smart interconnect has therefore become a critical piece in data center design. Given the performance boost it provides, it is much more cost effective to pay more money up front for smarter interconnect than to invest in a CPU-centric system that suffers from network overhead.
Which Interconnect to Use?
This leads to a debate that is starting to heat up over which interconnect is the ideal standard on which to design an HPC data center. InfiniBand has been the de-facto solution for high performance applications for nearly a decade and is the most used interconnect on the Top500 Supercomputers list. But now Omni-Path has emerged as a challenger to InfiniBand.
InfiniBand was one of the enablers of the original transitions from SMP to clusters and from single-core to multi-core technology, and it continues to lead the industry forward by implementing a Co-Design architecture to produce smart interconnect. With the new SHArP (Scalable Hierarchical Aggregation Protocol) technology, in-network computing manages and executes MPI collectives operations in the network, delivering 10X performance improvement for MPI and SHMEM/PAGS applications. The InfiniBand network effectively operates as a co-processor, leading to a breakthrough in building next generation data centers.
Omni-Path, on the other hand, is the same technology as the old technology, “InfiniPath” by Pathscale which was later bought and marketed by QLogic under the name “TrueScale”. It promulgates the old concept by being 100% CPU-dependent. Omni-Path completely depends on executing the networking tasks in the CPU instead of making the network more intelligent. This might improve a value proposition versus other CPU options, but it is not good for the efficiency of today’s applications and even more so for the future of the data center.
Moreover, as mentioned earlier, it makes more sense to pay more money up front for intelligent interconnect than to invest in a CPU-centric system such as Omni-Path. Even if Omni-Path were offered for free, the network overhead on the CPU hurts compute performance enough to produce significantly less return on the overall investment in the hardware (see Figure 1 as an example).
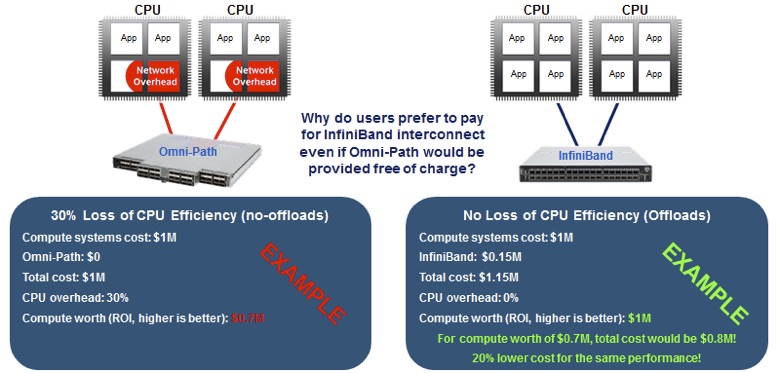
Figure 1: Given the performance degradation from CPU overhead in proprietary Omni-Path, InfiniBand is a much wiser investment
Conclusion
In today’s marketplace, intelligent interconnect is synonymous with InfiniBand. Omni-Path cannot offer a smart network because it loads everything onto the CPU, creating overhead that degrades performance. Ultimately, Omni-Path is only smart for those who sell it, since it require users to buy more CPUs to try and improve their overall performance, at much higher cost.
The smart move for data centers is to insist on a smart network, and for that you need InfiniBand.

