

Mark O’Connor demonstrates Allinea Software
Are supercomputers practical for Deep Learning applications? Over at the Allinea Blog, Mark O’Connor writes that a recent experiment with machine learning optimization on the Archer supercomputer shows that relatively simple models run at sufficiently large scale can readily outperform more complex but less scalable models.
I needed high performance computing expertise to see that the performance was limited by workload imbalance between the nodes triggered by late senders. I combined that with domain expertise in playing Pong to reach the insight that source of the imbalance could be eliminated without harming the model’s performance (it’s better to have a few learners lose a reward signal than a lot of learners sitting idle). This dynamic between HPC expertise and domain expertise is central to both the established world of scientific computing and to the newer world of deep learning. The reason Allinea focuses on making tools that researchers and HPC experts alike can use is precisely to enable this kind of insight in domains a lot more complex than Atari Pong. In fields from climate modeling through natural language processing to real honest-to-God rocket science teams of people work together and tools that help them communicate effectively about correctness and performance are, well, they’re pretty neat.
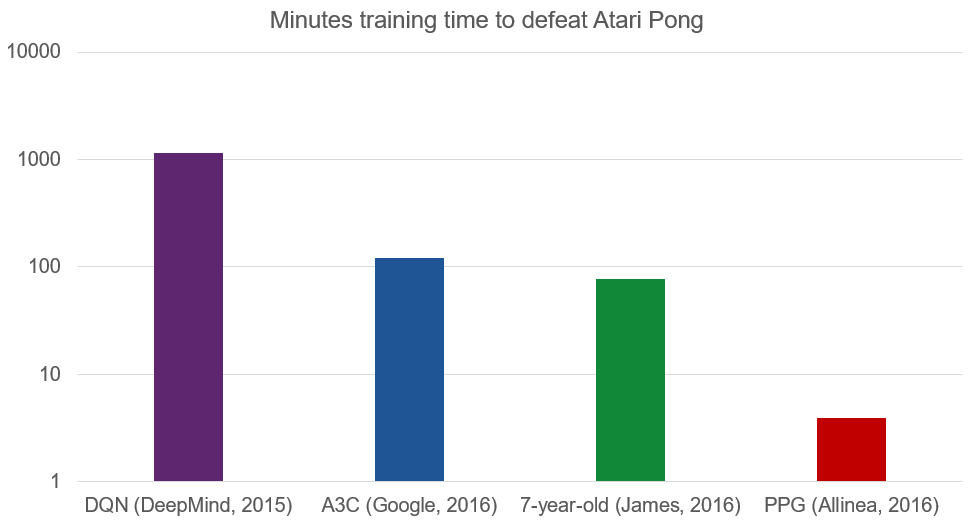
Wow! This chart is has a logarithmic scale because the pace of progress the last few years has been so rapid, but I never even dreamt that our little parallel algorithm would do this well. With a mere 1536 cores, our network learns to defeat Atari Pong from scratch in just 3.9 minutes. That’s less time than it takes a human to play a single game!
While the objective was to teach a machine how to play Pong, O’Connor says that the implications are very exciting for the HPC Community.
These remain open and interesting research questions of importance to AI in general because it’s clear that deep learning is going multi-node at very large scale. Google has been training single models on 500+ nodes on their proprietary infrastructure for some time in order to reduce the wall-clock training time and give their researchers an edge in innovating and finding better models. OpenAI have shared their infrastructure for scaling to hundreds of nodes on EC2. In the open science world, anyone running a HPC cluster can expect to see a surge in the number of people wanting to run deep learning workloads over the coming months.

