
 Over at Cluster Monkey, Douglas Eadline writes that the “free lunch” performance boost of Moore’s Law may indeed be back with the 1024-core Epiphany-V chip that will hit the market in the next few months.
Over at Cluster Monkey, Douglas Eadline writes that the “free lunch” performance boost of Moore’s Law may indeed be back with the 1024-core Epiphany-V chip that will hit the market in the next few months.
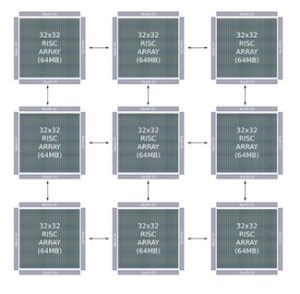
Adapteva’s Epiphany technology has taken a major leap forward. At 1024 cores, the announced Epiphany-V is gaining interest from many directions. The new version is based on the distributed shared Epiphany memory architecture that is comprised of an array of RISC processors communicating via a low-latency mesh Network-on-Chip. Each node in the processor array is a complete RISC processor capable of running an operating system as a Multiple Instruction, Multiple Data (“MIMD”) device. Epiphany uses a flat cache-less memory model in which all distributed memory is directly readable and writable by all processors in the system. For example, Epiphany packets are 136 bits wide and transferred between neighboring nodes in one and a half clock cycles. Packets consist of 64 bits of data, 64 bits of address, and 8 bits of control. Read requests puts a second 64-bit address in place of the data to indicate destination address for the returned read data.
Of course, single chip performance is one thing, but what about networking Epiphany-V chips together to form a supercomputer?
“As with previous Epiphany versions, multiple chips can be connected together at the board and system level using point to point links. As shown in Figure One, Epiphany-V has 128 point-to-point I/O links for chip to chip communication. Using an interconnected mesh of chips, the Epiphany 64-bit architecture supports systems with up to 1 Billion cores and 1 Petabyte (10ˆ15) of total memory. More detailed information can be found from the white paper. Besides the technical achievements, the design was completed at 1/100th the cost of the status quo and demonstrates an 80x advantage in processor density and 3.6x-15.8x advantage in memory density compared to state of the art processors.”
Sign up for our insideHPC Newsletter

