
In this special guest feature, Ken Strandberg writes that the Intel Omni-Path architecture is gaining momentum in the HPC marketplace.
 Intel Omni-Path Architecture (Intel OPA) volume shipments started a mere nine months ago in February of this year, but Intel’s high-speed, low-latency fabric for high-performance computing (HPC) has covered significant ground around the globe, including integration in HPC deployments making the Top500 list for June 2016. Intel’s fabric makes up 48 percent of installations running 100 Gbps fabrics on the Top500 June list, and they expect a significant increase in Top500 deployments, including one that could end up in the stratosphere among the top ten machines on the list.
Intel Omni-Path Architecture (Intel OPA) volume shipments started a mere nine months ago in February of this year, but Intel’s high-speed, low-latency fabric for high-performance computing (HPC) has covered significant ground around the globe, including integration in HPC deployments making the Top500 list for June 2016. Intel’s fabric makes up 48 percent of installations running 100 Gbps fabrics on the Top500 June list, and they expect a significant increase in Top500 deployments, including one that could end up in the stratosphere among the top ten machines on the list.
Many of the major HPC system OEMs integrating large and scalable machines have adopted the Intel fabric for their deployments. These include Dell, Lenovo, HPE, Cray, SGI, and Supermicro in the United States; Bull and Clustervision in Europe; Fujitsu in Japan; and Sugon, Inspur, and Huawei in China.
“Dell EMC is dedicated to helping customers accelerate their science, engineering and analytics by providing them highly scalable and well-integrated HPC systems. It’s no secret that interconnect can make all the difference in scalability,” said Onur Celebioglu, Director of HPC Engineering. “Intel Omni-Path Architecture is designed to scale cost-effectively from entry-level HPC clusters to larger systems with 10,000 nodes or more.”
Intel OPA is the chosen fabric for many leading installations around the globe, including Japan’s number one performing cluster—Oakforest-PACS—with 25 petaflops of peak performance across 8,208 nodes of Intel Xeon Phi processors. Oakforest-PACS was designed and built by Intel’s ecosystem partner Fujitsu. The Massachusetts Institute of Technology (MIT) is deploying a cluster with Intel OPA for analytics. “The MIT Lincoln Laboratory Supercomputing Center has a unique focus on interactive supercomputing for high-performance data analysis, and it is located in an extremely ‘green’ computing center,” said Dr. Jeremy Kepner, an MIT Lincoln Laboratory Fellow. “We’re always pushing the limits of technology and we look forward to continuing to work with Dell EMC to install a 648-node HPC system with early access to the Intel Xeon Phi processor and the Dell H-Series Omni-Path Architecture.”
One is Not Enough
At the Texas Advanced Computing Center (TACC), their Stampede-KNL (Stampede 1.5) cluster, taking position 117 on the Top500 for June 2016, was an upgrade to the original Stampede supercomputer cluster. Stampede-KNL adds 500 compute nodes with Intel Xeon processors and Intel Xeon Phi processors interconnected by Intel OPA. TACC’s Stampede 2 cluster, funded by a $30 million NSF award, will be an 18-petaflop machine built on Intel technologies, including Intel OPA.
“One is not enough” is a comment echoed by other customers. At the University of Hull in Yorkshire England, the institution’s Viper cluster built by Clustervision with Intel’s fabric is delivering performance beyond Hull’s expectations, according to Graeme Murphy, the university’s head of research and enterprise ICT services. “We’re already talking about Viper 2,” stated Murphy.
Penguin Computing’s win on the first Commodity Technology System program (CTS-1) for the U.S. government’s National Nuclear Security Agency (NNSA) chose Intel OPA for the clusters that began delivery to Lawrence Livermore National Laboratory earlier this year. HPE’s deployment of Bridges to Pittsburgh Supercomputing Center includes Intel OPA in a configuration serving a variety of workloads that include applications for HPC, Big Data Analytics, visualization, and others. Users actually got an early look in February at Intel OPA on Bridges with the MIDAS MISSION Public Health Hackathon. Developers were able to leverage the performance of the HPE server nodes with Intel OPA. Jay DePasse, a Hackathon participant and member of Team vzt said, “The MIDAS MISSION Public Health Hackathon was a great experience, and having access to resources like Bridges and its extremely high-speed Intel Omni-Path network was very helpful in producing data driven visualizations.”
The Forces Behind the Momentum
What drives the excitement and momentum behind Intel OPA is its performance, price/performance, scalability, and the customers’ satisfaction with their initial experiences after deployment.
Irrespective of the technology used to transfer data—that is, offloading or onloading—the bottom line is how does the application perform? Compared to standard InfiniBand EDR, many key HPC codes run as good or better on Intel OPA, based on testing of 24 HPC workloads done by Intel (see below and this application note for details and associated references). Part of this performance improvement is due to Intel’s implementation of intelligent onload/offload in the fabric. Depending on the data being moved, Intel OPA chooses the best implementation, using either offloading or onloading, to optimize the transfer for the best throughput needed by the application.
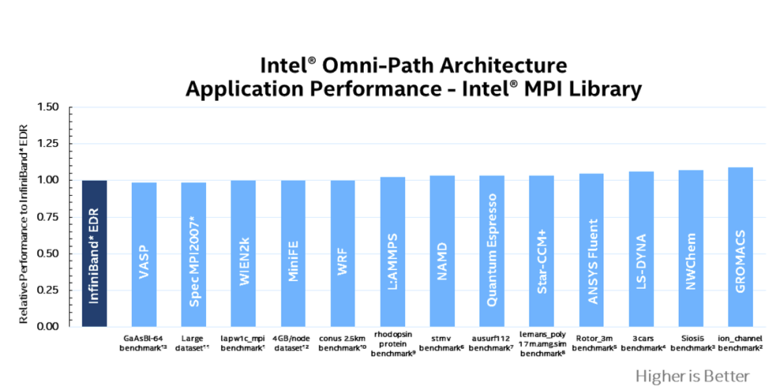
Figure 1. Application Performance – Intel® MPI – 16 Nodes (Used with permission by Intel Corp.)
Integrators and customers claim that competitive performance is not the only compelling reason to choose Intel OPA. The increased port density due to the Intel technology’s 48 radix switch silicon compared to InfiniBand’s 36-port switch, makes for a very attractive solution for large clusters, because it reduces the complexity and costs in the network’s design (see figure below). For Penguin Computing, Intel’s switch was very beneficial for the CTS design. “With a 48-port switch,” says Sid Mair, Senior VP of their Federal Systems Division, “we could spread out the nodes wider and use fewer layers across the racks. On 1,000 nodes, we needed only two layers of fabric instead of three. And, the bandwidth is so high that in some of the DOE installations they actually do a tapered fabric without impacting the running applications.” Nick Nystrom of the Pittsburgh Supercomputing Center echoes this sentiment regarding Bridges.[2]
![Figure 2. Intel 48 radix switch versus 36-port switch (Used with permission by Intel Corp.)[3]](https://insidehpc.com/wp-content/uploads/2016/11/fig2.png)
Figure 2. Intel 48 radix switch versus 36-port switch (Used with permission by Intel Corp.)[3]
Overall fabric performance combined with the reduced number of switches and cables required with Intel’s 48-port switch chip, add up to as much as 58% higher price-performance (based on GROMACS, 16 nodes)[5] for Intel OPA, according to Intel.
Scalability—Not a Problem
Both Stampede-KNL and Oakforest-PACS are clusters running hundreds and thousands of nodes, respectively, and over a half million cores, interconnected by Intel OPA— with record-setting performance by the Stampede machine. Clearly, performance, scalability, and stability are not an issue to date for this fabric technology. Intel OPA has proven itself so well in these installations that TACC has ordered a much larger cluster powered by Intel OPA.
Intel OPA has garnered significant industry support, and, according to Intel, this support will be shown at the upcoming Supercomputing conference in Salt Lake City. At least 30 companies will be showcasing Intel Omni-Path Architecture fabric in their booths. This level of onboarding by vendors illustrates both the attractiveness of the benefits of Intel Omni-Path Architecture fabric, as well as the effort Intel has invested in building a strong ecosystem around their fabric.
The Next Milestone
Over the last nine months, Intel, with Intel Omni-Path Architecture, has established a strong standing as the next-generation fabric technology for HPC. The community is looking forward to the release of the Top500’s November list at SC16 to see how Intel OPA continues to penetrate the HPC market.
Footnotes:
[1] http://www.intel.com/content/www/us/en/high-performance-computing-fabrics/omni-path-architecture-application-performance-mpi.html
[2] http://insidehpc.com/2016/06/building-bridges-to-the-future/
[3] Latency numbers based on Mellanox CS7500 Director Switch and Mellanox SB7700/SB7790 Edge switches. See www.Mellanox.com for more product information.
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance. *Other names and brands may be claimed as the property of others.
[4] Configuration assumes a 750-node cluster, and number of switch chips required is based on a full bisectional bandwidth (FBB) Fat-Tree configuration. Intel® OPA uses one fully-populated 768-port director switch, and Mellanox EDR solution uses a combination of 648-port director switches and 36-port edge switches. Intel and Mellanox component pricing from www.kernelsoftware.com, with prices as of May 5, 2016. Compute node pricing based on Dell PowerEdge R730 server from www.dell.com, with prices as of November 3, 2015. Intel® OPA pricing based on estimated reseller pricing based on projected Intel MSRP pricing at time of launch. * Other names and brands may be claimed as property of others.
[5] Intel® Xeon® Processor E5-2697A v4 dual-socket servers with 2133 MHz DDR4 memory. Intel® Turbo Boost Technology and Intel® Hyper Threading Technology enabled. BIOS: Early snoop disabled, Cluster on Die disabled, IOU non-posted prefetch disabled, Snoop hold-off timer=9. Red Hat Enterprise Linux Server release 7.2 (Maipo). Intel® OPA testing performed with Intel Corporation Device 24f0 – Series 100 HFI ASIC (B0 silicon). OPA Switch: Series 100 Edge Switch – 48 port (B0 silicon). GROMACS version 5.0.4 ion_channel benchmark. 16 nodes, 32 MPI ranks per node, 512 total MPI ranks. Intel® MPI Library 2017.0.064. Additional configuration details available upon request. All pricing data obtained from www.kernelsoftware.com October 20, 2016. All cluster configurations estimated via internal Intel configuration tool. Cost reduction scenarios described are intended as examples of how a given Intel-based product, in the specified circumstances and configurations, may affect future costs and provide cost savings. Circumstances will vary. Intel does not guarantee any costs or cost reduction. Fabric hardware assumes one edge switch, 16 network adapters and 16 cables.

