This is the third entry in an insideHPC series that delves into in-memory computing and the designs, hardware and software behind it. This series, compiled in a complete Guide available here, also covers five ways in-memory computing can save money and improve TCO. This column focuses on scaling software.
Scaling Software
The move away from the traditional single processor/memory design has fostered new programming paradigms that address multiple processors (cores). Existing single core applications need to be modified to use extra processors (and accelerators). Unfortunately there is no single portable and efficient programming solution that addresses both scale-up and scale-out systems.

Scale-Up Programming Tools
In general, because scale-up designs are an extension of the basic processor/memory design software is much easier to create and modify. While there are many tools available for scale-up programming, the most popular are OpenMP, pthreads, and OpenCL. It should be noted that these tools would not work across cluster nodes of a scale-out system. They are limited to a single in-memory domain.
Because scale-up designs are an extension of the basic processor/ memory design software is much easier to create and modify.
Pthreads – The thread model is a way for a program to split itself into two or more concurrent tasks. The tasks can be transparently run on a single core or in a time-shared mode on separate cores. On Linux and Unix systems, threads are often implemented using a POSIX Thread Library (pthreads). As a low level library, pthreads can be easily included in almost all programming applications. Threads provide the ability to share memory between sibling threads on scale-up systems. Software coding at the thread level is not without its challenges because “threaded” applications require attention to detail and considerable amounts of extra code to be added to the application.
OpenMP – Because native thread programing can be cumbersome, a higher-level abstraction has been developed called OpenMP. As with all higher-level approaches, there is the sacrifice of some flexibility for the ease of coding. At its core, OpenMP uses threads, but the details are hidden from the programmer. OpenMP is most often implemented as compiler directives in program comments. Typically, computationally heavy loops are augmented with OpenMP directives or hints (as comments) that the compiler uses to automatically “thread the loop”. This type of approach has the distinct advantage that it leaves the original program “untouched” (except for comment directives) and provides simple recompilation for a sequential (non-threaded) version where the OpenMP directives are ignored. OpenMP is available as part of the Fortran, C, and C++ languages and can now support both multi-core processors and accelerators.
OpenCL – A more recent addition to the scale-up programming toolbox is the OpenCL language. OpenCL is a C based language that allows the programmer to address both processors and accelerators. Unlike OpenMP, it is an explicit parallel programming language where the user must control many aspects of parallel operation. For this reason, it is mostly used for accelerator (or GPU) programming.
Scale-out Programming Tools
MPI (Message Passing Interface) – The most common scale-out programming tool is the MPI library that is available for Fortran, C/C++, Python and others. In contrast to threaded approaches, MPI uses a software library to send messages from one program to another. This approach is very effective on scale-out systems when processors do not share local memory. Many HPC applications have been modified to use MPI. Although developed for scale-out systems, MPI applications can be run on scale-up systems (although the same application written in OpenMP may run faster).
The below table illustrates the advantages of scale-up systems over scale-out systems with regard to software tools. The scale-up system can run both OpenMP (threaded) applications and MPI (messaging) applications using all system resources (cores and memory). A scale-out system can only run OpenMP applications on a single cluster node, thus limiting the scalability of user applications.
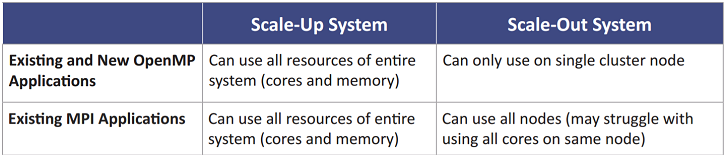
OpenMP and MPI applications on scale-up and scale-out systems
Over the next few weeks this series on in-memory computing will cover the following additional topics:
- In Memory Computing for HPC
- Scaling Hardware for In-Memory Computing
- Five Ways In-Memory Computing Saves Money and Improves TCO
You can also download the complete report, “insideHPC Research Report on In-Memory Computing: Five Ways In-Memory Computing Saves Money and Improves TCO,” courtesy of SGI and Intel.

