
 Today NEC Corporation announced that it has developed Aurora Vector Engine data processing technology that accelerates the execution of machine learning on vector computers by more than 50 times in comparison to Apache Spark technologies.
Today NEC Corporation announced that it has developed Aurora Vector Engine data processing technology that accelerates the execution of machine learning on vector computers by more than 50 times in comparison to Apache Spark technologies.
“Aurora Vector Engine technology enables users to quickly benefit from the results of machine learning, including the optimized placement of web advertisements, recommendations, and document analysis,” said Yuichi Nakamura, General Manager, System Platform Research Laboratories, NEC Corporation. “Furthermore, low-cost analysis using a small number of servers enables a wide range of users to take advantage of large-scale data analysis that was formerly only available to large companies.”
This newly developed data processing utilizes computing and communications technologies that leverage “sparse matrix” data structures in order to significantly accelerate the performance of vector computers in machine learning.
Furthermore, NEC developed middleware that incorporates sparse matrix structures in order to simplify the use of machine learning. As a result, users are able to easily launch this middleware from Python or Spark infrastructures, which are commonly used for data analysis, without special programming.
NEC’s next-generation vector computer is being developed to flexibly meet a wide range of price and performance needs. This data processing technology expands the capabilities of next-generation vector computers to include large-scale data analysis, such as machine learning, in addition to numerical calculation, the conventional specialty of vector computers.
New technology features include:
-
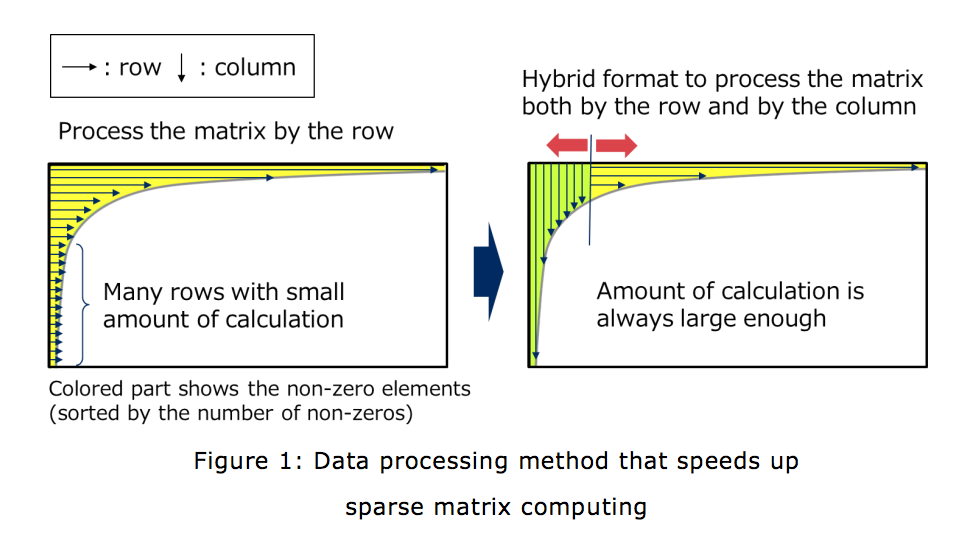
- Accelerates sparse matrix computing through the development of a method suitable for vector computers NEC developed a hybrid format using sparse matrix in which processing is appropriately executed by column or by row depending on the number of non-zero portions. This enables the high-speed processing of machine learning without decreasing the processing efficiency of vector computers.
-
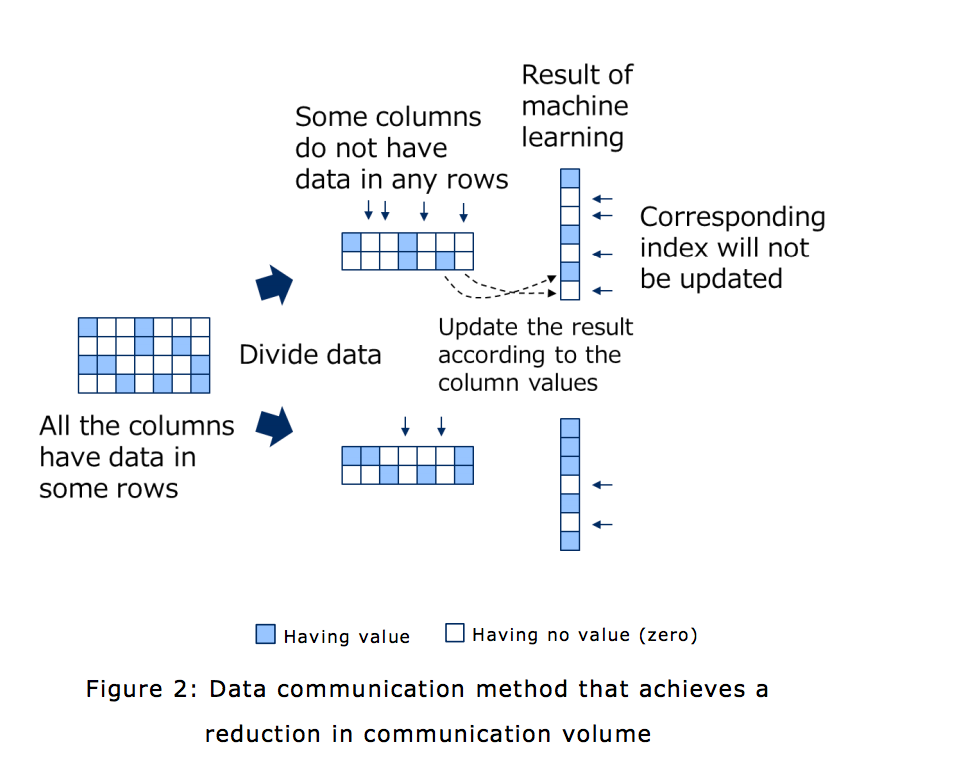
- Reduces communication volume in machine learning for sparse matrix In a sparse matrix that is used as input data in machine learning, columns occur that have no value in any row, after the division of the data for distributed processing. In machine learning processing, because the processing result is updated depending on the values in columns, the portions corresponding to the columns that have no value are not updated. By removing these non-updated portions from communication, the reduction of communication volume is achieved.
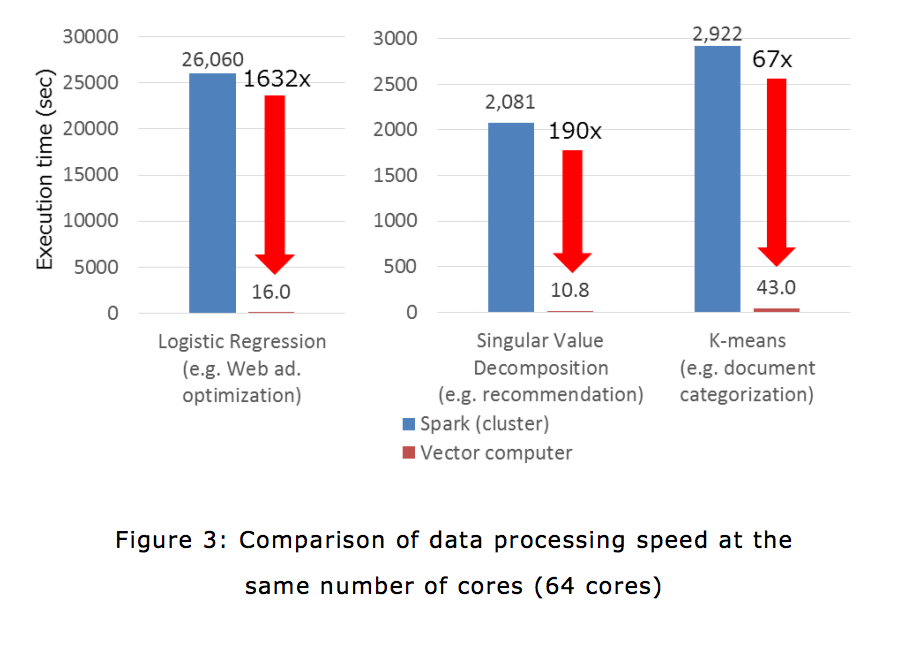
- Develops middleware incorporating the above technology By implementing this middleware using C++ and MPI, efficient processing can be executed. In addition, as is the case with Spark, the middleware has been designed so that parallel processing straddling multiple processors can be easily described. Moreover, the middleware can be launched Having value Having no value (zero) Figure 2: Data communication method that achieves a reduction in communication volume 3 from Spark and Python in the same format as the provided machine learning library. As for the execution time spent on machine learning, we compared a case in which Spark is executed in a cluster where multiple servers are connected and a case in which this middleware is executed in SX-ACE, a vector computer produced by NEC. It was found that the execution time of the latter is more than 50 times faster than that of the former.
NEC introduced this technology at the International Symposium on Parallel and Distributed Computing 2017 (ISPDC-2017) held in July 3-6 in Innsbruck.

