 It has always been a developers concern to feed the cpus or cores with data as fast as possible. Over time, both the CPUs and memory bandwidth have seen their respective speed increase dramatically. However, there is still the need for High Performance Computing types of applications to be architected and be aware of the need to keep the cpus humming with delivered data. An application can slow down dramatically if the CPUs are waiting for the data to be delivered, increasing the TCO of the entire system. HPC systems are meant to compute, not wait for data.
It has always been a developers concern to feed the cpus or cores with data as fast as possible. Over time, both the CPUs and memory bandwidth have seen their respective speed increase dramatically. However, there is still the need for High Performance Computing types of applications to be architected and be aware of the need to keep the cpus humming with delivered data. An application can slow down dramatically if the CPUs are waiting for the data to be delivered, increasing the TCO of the entire system. HPC systems are meant to compute, not wait for data.
Memory bandwidth to the CPUs has always been important. There were typically CPU cores that would wait for the data (if not in cache) from main memory. However, with the advanced capabilities of the Intel Xeon Phi processor, there are new concepts to understand and take advantage of.
The Intel Xeon Phi processor has two types of memory in addition to the traditional L1 and L2 caches. These are referred to at DDR and MCDRAM. Each CPU in the Intel Xeon Phi processor has access to both types of memory and the MCDRAM can be configured for different purposes. DDR is traditional memory and the Intel Xeon Phi processor contains up to 384 GB of this type of memory. The MCDRAM memory can be used in two different ways and 16 GB are available.
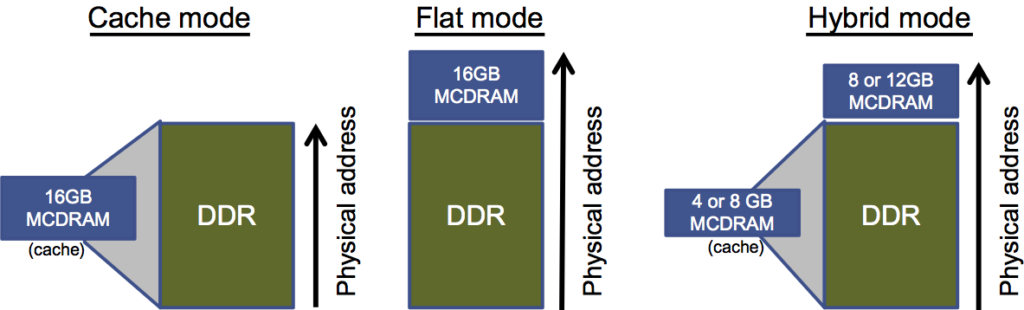
The first is to treat the MCDRAM as a third level cache. When there are data misses from the L2 cache, the system will look for the data in the 3rd level cache. This could be considered the more traditional approach to using MCDRAM. The second method is to use MCDRAM in flat mode, where the memory is mapped to the physical address space of the process. There is also the hybrid mode where MCDRAM can be used in both methods, where half of the memory is used as a L3 cache and the other half as flat memory.
[clickToTweet tweet=”Understand the memory in the Intel Xeon Phi processor. #intelxeonphi” quote=”Understanding the different types of memory in the Intel Xeon Phi processor is fundamental to obtaining performance gains.”]Since memory bandwidth can be so important in the overall performance of an application, understanding what is happening in these different scenarios is very important as the application is being developed and tested. If the application’s data fits mostly in L2 cache, the bandwidth to and from memory will be small and not significant in the overall performance. Computing the bandwidth when the MCDRAM is configured in flat mode is fairly straightforward. When the MCDRAM is used either entirely or partially as an L3 cache, then the calculation is more complex, as the eviction of cache lines need to be taken into account.
Knowing the theoretical bandwidth of the system can help developers to understand how an application is performing. There are a number of events that can be monitored when the application is running that will give information as to the memory bandwidth. If the observed bandwidth is significantly less than expected, this probably points to poor spatial locality. If a large number of TLB misses are observed, this will become obvious with the events that are generated. The developer should understand that the MCDRAM bandwidth is significantly higher than the DDR bandwidth and should be able to adjust the algorithm implementation accordingly. By placing data structures in MCDRAM, the performance can be improved significantly.
When looking at the performance of a complex application, it is important to understand the memory access patterns. Previously, there was not much flexibility in how memory was used. Now, with the Intel Xeon Phi processor, much more flexibility is available to the developer and system administrators, that can greatly increase performance.
Download your free 30-day trial of Intel® Parallel Studio XE

