
VP, High Performance Computing & Data Analytics, IBM Cognitive Systems
Over at IBM, Sumit Gupta writes that the company has enabled record-breaking image recognition capabilities that make Deep Learning much more practical at scale.
It currently may take days or even weeks to train large AI models with big data sets to get the right accuracy levels. At the crux of this problem is a technical limitation. The popular open-source deep-learning frameworks do not seem to run as efficiently across multiple servers. So, while most data scientists are using servers with four or eight GPUs, they can’t scale beyond that single node. For example, when we tried to train a model with the ImageNet-22K data set using a ResNet-101 model, it took us 16 days on a single Power Systems server (S822LC for High Performance Computing) with four NVIDIA P100 GPU accelerators. 16 days – that’s a lot of time you could be spending elsewhere. And since model training is an iterative task, where a data scientist tweaks hyper-parameters, models, and even the input data, and trains the AI models multiple times, these kinds of long training runs delay time to insight and can limit productivity.
To achieve these results, IBM Research built a “Distributed Deep Learning” (DDL) library that hooks into popular open source machine learning frameworks like TensorFlow, Caffe, Torch and Chainer. DDL enables these frameworks to scale to tens of IBM servers leveraging hundreds of GPUs.
Effectively, IBM Research has invented the jet engine of deep learning. With the DDL library, it took us just 7 hours to train ImageNet-22K using ResNet-101 on 64 IBM Power Systems servers that have a total of 256 NVIDIA P100 GPU accelerators in them. 16 days down to 7 hours changes the workflow of data scientists. That’s a 58x speedup!
The distributed deep learning (DDL) library is available as a technology preview in our latest version 4 release of the PowerAI deep learning software distribution. DDL presents an application programming interface (API) that each of the deep learning frameworks can hook into, to scale across multiple servers. PowerAI makes this cluster scaling feature available to organizations using deep learning for training their AI models.
And it scales efficiently – Running across multiple nodes is only half the battle, doing it efficiently is the most important half. Fortunately, building upon a rich experience in HPC and analytics, IBM Research was able to scale deep learning frameworks across up to 256 GPUs with up to 95 percent efficiency!
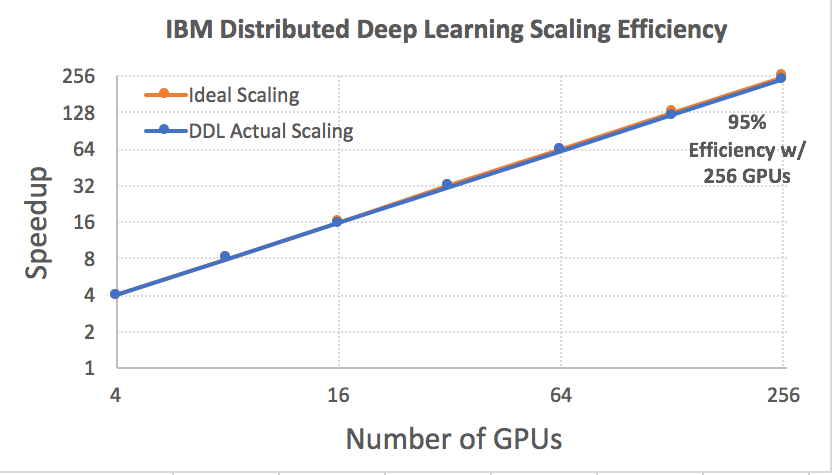
Figure 1: Scaling results using Caffe to train a ResNet-50 model using the ImageNet-1K data set on 64 Power Systems servers that have a total of 256 NVIDIA P100 GPU accelerators in them.
PowerAI is available to try on the Nimbix Power cloud. You can also try an IBM Power Server for yourself.
Sign up for our insideHPC Newsletter

