The following guest article from Intel explores how businesses can optimize AI applications, integrate them with their traditional workloads and join the AI revolution.
Many organizations are looking for an efficient and cost-effective foundation for developing, deploying and scaling AI applications and integrating them with traditional workloads.
Organizations with deep pockets, deep expertise, and high-end computing resources have developed deep learning applications, such as complex games,[1] and practical tasks, such as image and speech recognition. Many of these applications are impacting our everyday lives, including introducing human-like capabilities into personal digital assistants, online preference engines, fraud detection systems and more.
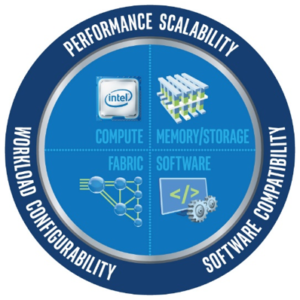
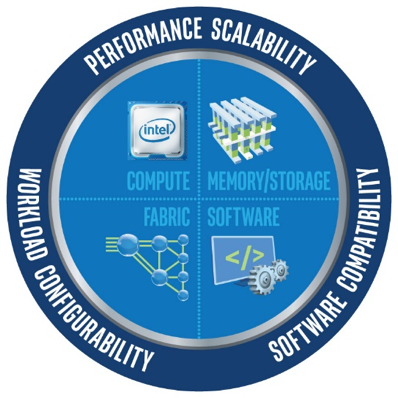
The Intel Scalable System Framework brings hardware and software together to support the next-generation of AI applications on simpler, more affordable, and massively scalable HPC clusters.
However, for the AI revolution to move into the mainstream, cost and complexity must be reduced, so smaller organizations can afford to develop, train and deploy powerful deep learning applications.
It’s a tough challenge. Interest in AI is high, technologies are in flux and no one can reliably predict what those technologies will look like even five years from now. How do you simplify and drive down costs in such an inherently complex and changing environment? How do you ensure the advances in performance are accompanied by comparable leaps in scalability to support growing data volumes and larger neural networks? To address this need, Intel is driving innovation across the entire HPC solution stack through the Intel Scalable System Framework (Intel SSF).
[clickToTweet tweet=”Intel – For the AI revolution to move into the mainstream, cost and complexity must be reduced.” quote=”Intel – For the AI revolution to move into the mainstream, cost and complexity must be reduced.”]
Optimized Software Building Blocks that are Flexible—and Fast
Most of today’s deep learning algorithms were not designed to scale on modern computing systems. Intel has been addressing those limitations by working with researchers, vendors, and the open-source community to parallelize and vectorize core software components for Intel Xeon processors and Intel Xeon Phi processors.
Optimized tools, libraries, and frameworks for HPC often provide order-of-magnitude and higher performance gains, potentially reducing the cost and complexity of the required hardware infrastructure. They also integrate more easily into standards-based environments, so new AI developers have less to learn, deployment is simpler, and costs are lower.
Optimized software development tools help, but deep learning applications are compute-intensive, data sets are growing exponentially, and time-to-results can be key to success.
Optimized software development tools help, but deep learning applications are compute-intensive, data sets are growing exponentially, and time-to-results can be key to success. HPC offers a path to scaling compute power and data capacity to address these requirements.
However, combining AI and HPC brings additional challenges. AI and HPC have grown up in relative isolation, and there is currently limited overlap in expertise between the two areas. Intel is working with both communities to provide a better and more open foundation for mutual development.
Powerful Hardware to Run It All
Of course, software can only be as powerful as the hardware that runs it. Intel is delivering disruptive new capabilities in its processors and integrating these advances into Intel SSF.
Choosing the right processors for specific workloads is important. Current options include:
- Intel Xeon Scalable processors for inference engines and for some training workloads. Intel Xeon processors already support 97 percent of all AI workloads[2]. With more cores, more memory bandwidth, an option for integrated fabric controllers, and ultra-wide 512-bit vector support, the new Intel Xeon Scalable processors (formerly code name Skylake) provide major advances in performance, scalability, and flexibility. With their broad interoperability, they provide a powerful and agile foundation for integrating AI solutions into other business and technical applications.
- Intel Xeon Phi processors for training large and complex neural networks. With up to 72 cores, 288 threads, and 512-bit vector support—plus integrated high bandwidth memory and fabric controllers—these processors offer performance and scalability advantages versus GPUs for neural network training. Since they function as host processors and run standard x86 code, they simplify implementation and eliminate the inherent latencies of PCIe-connected accelerator cards.
- Optional accelerators for agile infrastructure-optimization. Intel offers a range of workload-specific accelerators, including programmable Intel FPGAs, that can evolve along with workloads to meet changing requirements. These optional add-ons for Intel Xeon processor-based servers bring new flexibility and efficiency for supporting AI and many other critical workloads.
Learn more about the innovation Intel is driving across the entire HPC solution stack including compute, memory, software and fabric.
[1] For example, Libratus, the application that beat five of the world’s top poker players, was created by a team at Carnegie Mellon University and relied on 600-nodes of a University of Pittsburgh supercomputer for overnight processing during the competition.
[2] Based on Intel internal estimates.

