This is the first of a series that survey the landscape of HPC and AI. The full report includes an in-depth review of the opportunities and challenges of AI-HPC.

Download the full report
It is important to understand what we mean by AI as this is a highly overloaded term. It is truly remarkable that machines, for the first time in human history, can deliver better than human accuracy on complex ‘human’ activities such as facial recognition 4, and further that this better-than-human capability was realized solely by providing the machine with example data in what is called a training set. This has driven the AI explosion due to an increase in compute capability and architectural advancements, innovation in AI technologies, and the increase in available data.
The term ‘artificial Intelligence’ has been associated with machine learning and deep learning technology for decades. Machine learning describes the process of a machine programming itself (e.g. learning) from data. The popular phrase ‘deep learning’ encompasses a subset of the more general term ‘machine learning’.
[clickToTweet tweet=”The term ‘artificial Intelligence’ has been associated with machine learning technology for decades. ” quote=”The term ‘artificial Intelligence’ has been associated with machine learning technology for decades. “]
Originally, deep learning was used to describe the many hidden layers that scientists used to mimic the many neuronal layers in the brain. Since then, it has become a technical term used to describe certain types of artificial neural networks (ANNs) that have many hidden or computational layers between the input neurons, where data is presented for training or inference and the output neuron layer where the numerical results can be read. The numerical values of the “weights” (also known as parameters of the ANNs) that guide the numerical results close to the “ground truth” contain the information that companies use to identify faces, recognize speech, read text aloud, and provide a plethora of new and exciting capabilities.
Originally, deep learning was used to describe the many hidden layers that scientists used to mimic the many neuronal layers in the brain.
The forms of AI that use machine learning require a training process that fits the ANN model to the training set with low error. This is done by adjusting the values or parameters of the ANN. Inferencing refers to the application of that trained model to make predictions, classify data, make money, etcetera. In this case, the parameters are kept fixed based on a fully trained model.
Inferencing can be done quickly and even in real-time to solve valuable problems. For example, the following graphic shows the rapid spread of speech recognition (which uses AI) in the data center as reported by Google Trends. Basically, people are using the voice features of their mobile phones more and more.
Inferencing also consumes very little power, which is why forward thinking companies are incorporating inferencing into edge devices, smart sensors and IoT (Internet of Things) devices.6 Many data centers exploit the general purpose nature of CPUs like Intel Xeon processors to perform volume inferencing in the data center or cloud. Others are adding FPGAs for extremely low-latency volume inferencing.
Training on the other hand is very computationally expensive and can run 24/7 for very long periods of time (e.g. months or longer). It is reasonable to think of training as the process of adjusting the model weights of the ANN by performing a large number of inferencing operations in a highly parallel fashion for a fixed training set during each step of the optimization procedure and readjusting the weights that result in minimizing the error from the ground truth. Thus, parallelism and scalability as well as floating-point performance are key to finding the model that accurately represents the training data quickly with a low error.
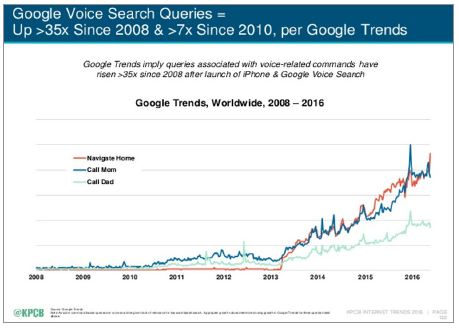
Figure 1: Google Voice Search Queries
Now you should understand that all the current wonders of AI are the result of this model fitting, which means we are really just performing math. It’s best to discard the notion that humans have a software version of C3PO from Star Wars running in the computer. That form of AI still resides in the future. Also, we will limit ourselves to the current industry interest in ANNs, but note that there are other, less popular, forms of AI such as Genetic Algorithms, Hidden Markov Models, and more.
Scalability is a requirement as training is a “big data” problem
Scalability is a requirement as training is considered a big data problem because as demonstrated in the paper, How Neural Networks Work, the ANN is essentially fitting a complex multidimensional surface7.
[clickToTweet tweet=”Scalability is a requirement as training is considered a big data problem. #AI #HPC” quote=”Scalability is a requirement as training is considered a big data problem. #AI #HPC”]
People are interested in using AI to solve complex problems, which means the training process needs to fit very rough, convoluted and bumpy surfaces. Think of a boulder field. There are lots and lots of points of inflection—both big and small that define where the all the rocks and holes are as well as all their shapes. Now increase that exponentially as we attempt to fit a hundred or thousand dimensional ‘boulder field’.

People are interested in using AI to solve complex
problems, which means the training process needs to fit very rough, convoluted and bumpy surfaces.
Thus, it takes lots of data to represent all the important points of inflection (e.g. bumps and crevasses) because there are simply so many of them. This explains why training is generally considered a big data problem. Succinctly: smooth, simple surfaces require little data, while most complex real-world data sets require lots of data.
Accuracy and time-to-model are all that matter when training
It is very important to understand that time-to-model and the accuracy of the resulting model are really the only performance metrics that matter when training because the goal is to quickly develop a model that represents the training data with high accuracy.
For machine learning models in general, it has been known for decades that training scales in a near-linear fashion, which means that people have used tens and even hundreds of thousands of computational nodes to achieve petaflop/s training performance.8 Further, there are well established numerical methods such as Conjugate Gradient and L-BGFS to help find the best set of model parameters during training that represent the data with low error. The most popular machine learning packages make it easy to call these methods.
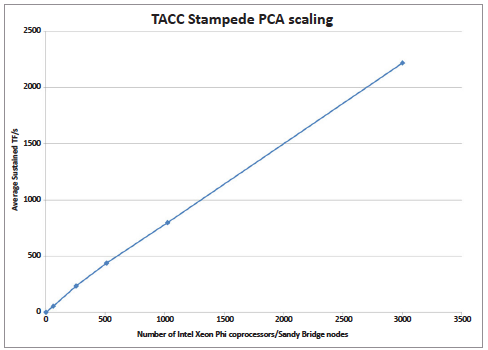
Figure 3: Example scaling to 2.2 PF/s on the original TACC Stampede Intel
Xeon PhiTM coprocessor computer (Courtesy TechEnablement)
A breakthrough in deep learning scaling
For various reasons, distributed scaling has been limited for deep learning training applications. As a result, people have focused on hardware metrics like floating-point, cache, and memory subsystem performance to distinguish which hardware platforms are likely to perform better than others and deliver that desirable fast time-to-model.
How fast the numerical algorithm used during training reaches (or converges to) a solution greatly affects time-to-model. Today, most people use the same packages (e.g. Caffe*, TensorFlow*, Theano, or the Torch middle-ware), so the convergence rate to a solution and accuracy of the resulting solution have been neglected. The assumption is that the same software and algorithms shouldn’t differ too much in convergence behavior across platforms,9 hence the accuracy of the models should be the same or very close. This has changed as new approaches to distributed training have disrupted this assumption.
A recent breakthrough in deep-learning training occurred as a result work by collaborators with the Intel Parallel Computing Center (Intel PCC) that now brings fast and accurate distributed deep learning training to everyone, regardless if they run on a leadership class supercomputer or on a workstation.
Scaling deep-learning training from single-digit nodes just a couple of years back to almost 10,000 nodes now, adding up to more than ten petaflop/s is big news.” – Pradeep Dubey, Intel Fellow and Director of Parallel Computing Lab
Succinctly, a multiyear collaboration between Stanford, NERSC, and Intel established10 that the training of deep-learning ANNs can scale to 9600 computational nodes and deliver 15PF/s of deep learning training performance. Prior to this result, the literature only reported scaling of deep learning training to a few nodes11. Dubey observed “scaling deep-learning from a few nodes to more than ten petaflop/s is big news” as deep learning training is now a member of the petascale club.
The insideHPC Special Report on AI-HPC will also cover the following topics over the next few weeks:
- Inferencing, platforms and infrastructure
-
Customer Use Cases
-
The AI Software Ecosystem
-
Hardware to Support the AI Software Ecosystem
Download the full report: “insideHPC Special Report: AI-HPC is Happening Now” courtesy of Intel.

