

Cosmos code developer Chris Fragile is a professor in the Physics and Astronomy Department of the College of Charleston.
In this TACC podcast, Cosmos code developer Chris Fragile joins host Jorge Salazar for a discussion on how researchers are using supercomputers to simulate the inner workings of Black holes.
“Black holes make for a great space mystery. They’re so massive that nothing, not even light, can escape a black hole once it gets close enough. A great mystery for scientists is the evidence of powerful jets of electrons and protons that shoot out of the top and bottom of some black holes. Yet no one knows how these jets form. Computer code called Cosmos now fuels supercomputer simulations of black hole jets and is starting to reveal the mysteries of black holes and other space oddities.”
For this simulation, the manycore architecture of KNL presents new challenges for researchers trying to get the best compute performance, according to Damon McDougall, a research associate at TACC and also at the Institute for Computational Engineering and Sciences, UT Austin. Each Stampede2 KNL node has 68 cores, with four hardware threads per core. That’s a lot of moving pieces to coordinate.
This is a computer chip that has lots of cores compared to some of the other chips one might have interacted with on other systems,” McDougall explained. “More attention needs to be paid to the design of software to run effectively on those types of chips.”
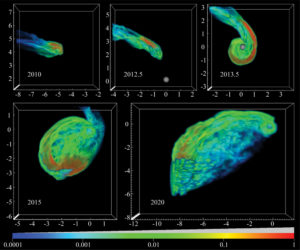
Time-series image showing the tidal disruption of a gas cloud by the supermassive black hole at the center of the Milky Way (Chris Fragile)
Through ECSS, McDougall has helped Fragile optimize CosmosDG for Stampede2. “We promote a certain type of parallelism, called hybrid parallelism, where you might mix Message Passing Interface (MPI) protocols, which is a way of passing messages between compute nodes, and OpenMP, which is a way of communicating on a single compute node,” McDougall said. “Mixing those two parallel paradigms is something that we encourage for these types of architectures. That’s the type of advice we can help give and help scientists to implement on Stampede2 though the ECSS program.”
“By reducing how much communication you need to do,” Fragile said, “that’s one of the ideas of where the gains are going to come from on Stampede2. But it does mean a bit of work for legacy codes like ours that were not built to use OpenMP. We’re having to retrofit our code to include some OpenMP calls. That’s one of the things Damon has been helping us try to make this transition as smoothly as possible.”

