This feature continues our series of articles that survey the landscape of HPC and AI. This post focuses on use cases that explore AI systems designed to learn in a limited information environment.

Carnegie Mellon University and learning in a limited information environment
Being able to collect large amounts of data from a simulation or via automated empirical observations like gene sequencers is a luxury that is not available to some HPC scientists. AI systems that can compete against and beat humans in limited information games have great potential, because so many activities between humans happen in the context of limited information such as financial trading and negotiations and even the much simpler task of buying a home.
Some scientists are utilizing games and game theory to address the challenges of learning in a limited information environment. In particular the Nash equilibrium helps augment information about behavior based on rational player behavior rather than by the traditional AI systems approach of collecting extensive amounts of data. In addition, this approach can address issues of imperfect recall, which poses a real problem for data-driven machine learning because human forgetfulness can invalidate much of a training set of past sampled behavioral data.
“In the area of game theory,” said Professor Tuomas Sandholm (Professor, Carnegie Mellon University), “No-Limit Heads-Up Texas Hold ‘em is the holy grail of imperfect-information games.” In Texas Hold ‘em, players have a limited amount of information available about the opponents’ cards because some cards are played on the table and some are held privately in each player’s hand. The private cards represent hidden information that each player uses to devise their strategy. Thus, it is reasonable to assume that each player’s strategy is rational and designed to win the greatest amount of chips.
[clickToTweet tweet=”AI systems that can compete against and beat humans in limited information games have great potential. #HPC” quote=”AI systems that can compete against and beat humans in limited information games have great potential. #HPC”]
In January of this year, some of the world’s top poker champions were challenged to 20 days of No-limit Heads-up Texas Hold ‘em poker at the Brains versus Artificial Intelligence tournament in Pittsburgh’s Rivers Casino. Libratus, the artificial intelligence (AI) engine designed by Professor Sandholm and his graduate student, beat all four opponents, taking away more than $1.7 million in chips.
Libratus is an AI system designed to learn in a limited information environment. It consists of three modules:
- A module that uses game-theoretic reasoning, just with the rules of the game as input, ahead of the actual game, to compute a blueprint strategy for playing the game. According to Sandholm, “It uses Nash equilibrium approximation, but with a new version of the Monte Carlo counterfactual regret minimization (MCCRM) algorithm that makes the MCCRM faster, and it also mitigates the issue of involving imperfect recall abstraction.”
- A subgame solver that recalculates strategy on the fly so the software can refine its blueprint strategy with each move.
- A post-play analyzer that reviews the opponent’s plays that exploited holes in Libratus’s strategies. “Then, Libratus re-computes a more refined strategy for those parts of the stage space, essentially finding and fixing the holes in its strategy a module that uses game-theoretic reasoning, just with the rules of the game as input, ahead of the actual game, to compute a blueprint strategy for playing the game,” stated Sandholm.
This is definitely an HPC problem. During tournament play, Libratus consumed 600 of Pittsburgh Supercomputing Center’s Bridges supercomputer nodes, it utilized 400 nodes for the endgame solver, and 200 for the self-learning module (e.g. the third module). At night, Libratus consumed all 600 nodes for the post-play analysis.
Sandholm also mentioned the general applicability of Libratus beyond poker: “The algorithms in Libratus are not poker-specific at all, the research involved in finding, designing, and developing application independent algorithms for imperfect information games is directly applicable to other two player, zero sum games, like cyber security, bilateral negotiation in an adversarial situation, or military planning between us and an enemy.” For example, Sandholm and his team have been working since 2012 to steer evolutionary and biological adaptation to trap diseases. One example is to use a sequence of treatments so that T-cells have a better chance of fighting a disease.
Deepsense.ai and reinforcement learning
A team from deepsense.ai utilized asynchronous reinforcement learning and TensorFlow running on CPUs to learn to play classic Atari games. The idea, described on the deepsense.ai blog, was to use multiple concurrent environments to speed up the training process while interacting with these real-time games. “This work provides a clear indication of the capabilities of modern AI and has implications for using deep learning and image recognition techniques to learn in other live visual environments”, explains Robert Bogucki, CSO at deepsense.ai.
The key finding is that by distributing the BA3C reinforcement learning algorithm, the team was able to make an agent rapidly teach itself to play a wide range of Atari games, by just looking at the raw pixel output from the game emulator. The experiments were distributed across 64 machines, each of which had 12 Intel CPU cores. In the game of Breakout, the agent achieved a superhuman score in just 20 minutes, which is a significant reduction of the single-machine implementation learning time.
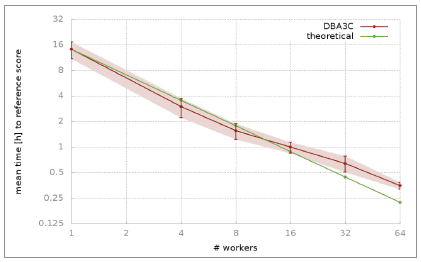
Mean time DBA3C algorithm needed to achieve a score of 300 in
Breakout (an average score of 300 needs to be obtained in 50 consecutive tries). The green line shows the theoretical scaling in reference to a single machine implementation.
Training for Breakout on a single computer takes around 15 hours, bringing the distributed implementation very close to the theoretical scaling (assuming computational power is maximized, using 64 times more CPUs should yield a 64-fold speed-up). The graph below shows the scaling for different numbers of machines. Moreover, the algorithm exhibits robust results on many Atari environments, meaning that it is not only fast, but can also adapt to various learning tasks.
The insideHPC Special Report on AI-HPC will also cover the following topics over the next few weeks:
- An Overview of AI in the HPC Landscape
- AI and HPC: Inferencing, Platforms & Infrastructure
- AI Technology: The Answer to Diffusion Compartment Imaging Challenges
- The AI Software Ecosystem
- Hardware to Support the AI Software Ecosystem
Download the full report: “insideHPC Special Report: AI-HPC is Happening Now” courtesy of Intel.

