
In this special guest feature, Siddhartha Jana summarizes the key findings of the first-of-its-kind survey on Energy and Power Aware Job Scheduling and Resource Management. You can watch a talk on this information from SC17 entitled “State of the Practice: Energy and Power Aware Job Scheduling and Resource Management.”

Siddhartha Jana is an HPC Research Scientist and a member of the Energy Efficient HPC Working Group, which now has more than 700 members in the Americas, Europe, Asia, Africa, and Australia.
The Energy Efficient HPC Working Group (EE HPC WG) has recently announced the findings of a global survey that was conducted during 2016-2017. The goal of this year-long survey was to investigate the active investments by HPC centers in enabling energy and power management within their software stack, especially the job schedulers and resource managers. The focus was on solutions adopted within the actual HPC system itself, and not the infrastructure supporting the entire facility that houses the system. The results of this survey were published as a white paper, a poster, and were also discussed, during the SC17 Birds-of-a-Feather session.
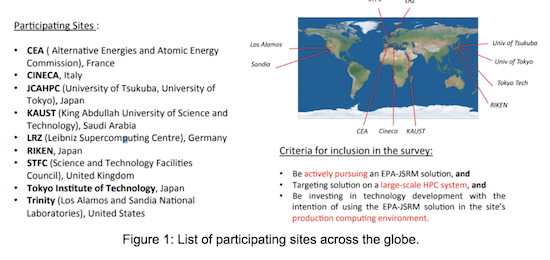
Figure 1 below lists the various sites that participated in this survey. These sites all met the following criteria:
- Actively pursuing EPA-JSRM (Energy- and Power-Aware Job Scheduling and Resource Management) solutions
- Targeting the solution on a large-scale HPC system
- Investing in technology development with the intention of using the EPA-JSRM solution in a production computing environment.
Out of the multiple questions covered in the survey, this article focuses on (1) the rationale behind investing in JSRM solutions, and (2) the implementations of the adopted solutions. For more details, the reader is directed to the white paper.
1. General structure of an EPA-JSRM solution
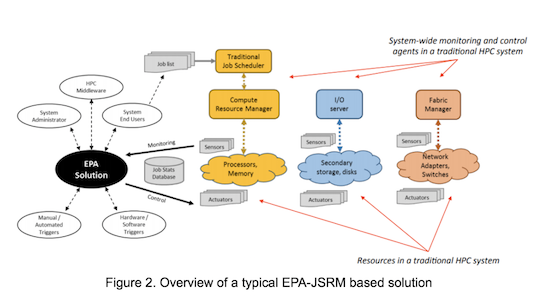
Figure 2 below depicts the induction of a typical energy- and power-aware solution into a traditional HPC system. In order to design a system-wide software solution, the natural first step is to explore opportunities for extending software agents that already cater to the management of system resources. Examples of these include the job scheduler/ resource manager, the I/O servers, and the fabric manager. The scope of this survey was to explore solutions incorporated within traditional job schedulers and resource managers.
As depicted in the figure, a typical EPA-JSRM solution includes power monitoring (via sensors) and control mechanisms (via actuators). The power control approach may be triggered (via hardware or software) either manually (by end users, system administrators) or automatically (by runtime framework, middleware).
2. Motivation behind investing in EPA-JSRM solutions
One of the primary challenges for exascale is the total cost and variability associated with the power consumed by both the HPC system, and the additional infrastructure supporting it. The motivation for controlling these costs differs drastically from one site to another. For some sites, external factors such as shortage of electricity, natural disasters (e.g. tsunamis and earthquakes), and government-issued mandates limit the supply of power. For others, limitations in the design of the facility that houses the system can lead to power shortages. Some sites are driving research efforts in this field with the goal of mitigating the impact of computation on the environment. Another motivation is to reduce electricity bill costs in order to improve future purchasing power for compute resources. Even sites that are not facing an immediate shortage of power are driven by an active interest in staying “ahead of the curve,” to improve system reliability and resiliency.
3. EPA-JSRM solutions adopted by HPC centers
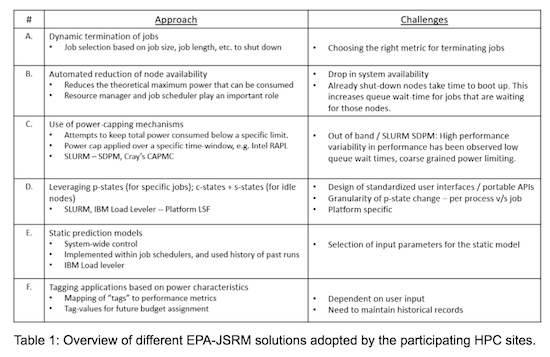
Table 1 summarizes the different approaches along with their challenges, as reported by the participating sites. It must be noted that the use of these approaches are not mutually exclusive: some of the participating sites have reported using a combination of these techniques. They are briefly discussed below.
3.1. Dynamic Termination of Jobs
One brute-force method of tackling system-wide power constraint is to actively.detect occasions where the total system power-draw approaches the constraining limit, and to terminate specific jobs to avoid the limit. The list of candidate jobs that are selected for such termination depend on a number of parameters such as job length, job size, etc. Choosing the right set of parameters, and explaining the rationale behind forced termination to the end-users are the main challenges with this approach. In addition, the power spent on incomplete execution of applications remains irretrievable.
3.2. Automated reduction of node availability
Another approach is to limit the total number of compute nodes available for job allocation. Limiting the node-count, either dynamically, or during queue release, reduces the theoretical maximum value of the total power consumption by the system. The advantage of this approach over the one above is that jobs do not have to be forcefully shut down once allocated to a compute node. The downside however, is that the drop in total node-count reduces the system utilization. Also, due to a shortage of compute resources, newly submitted jobs spend a longer time waiting in the job queue, which in turn affects the productivity of the end users.
3.3. Use of power capping mechanisms
An alternative to previous solutions is to leverage specific power control “knobs” which are exposed by the underlying hardware. One popular approach (commonly referred to as ‘power capping’), is to design the software stack to communicate specific power values to the hardware, either using in-band or out-of-band channels. The hardware then attempts to adhere to this request, subject to the a number of constraints imposed by the architecture design, application behavior, etc. Frameworks and/or hardware features that were reported as being used by the sites include – Intel’s RAPL (Running Average Power Limiting), Cray’s CAPMC, and Slurm’s Dynamic Power Management (SDPM). It was reported that using out-of-band solutions led to efficient job queue management, but at the cost of high performance variability. Using in-band solutions (like Intel’s RAPL) was reported to give more stable and reproducible results.
3.4. Leveraging hardware-specific performance and idle states (P-states, C-states, S-states)
System hardware components are capable of operating at multiple operating states. Performance states like P-states map to different discrete operating frequencies that can be chosen based on an application’s demand. These frequencies map to different voltage levels, which in turn, impact the power consumed by the hardware component. Some system components also provide multiple idle states like C-states and S-states, which lead to power savings in case of zero activity. Some of the HPC sites have reported using software-driven techniques that leverage these hardware-tuning knobs to drive energy efficient execution of their applications. To facilitate this, system-wide resource managers like Slurm and IBM Loadleveler (Platform LSF) were used on Intel and IBM machines, respectively.
3.5 Static Prediction Models:
Some sites have reported incorporating prediction models within their system-wide resource managers. The purpose of the model is to predict a set of system configuration parameters (e.g. ideal operating frequency, power caps, etc) for a given application. These techniques require maintenance of historic data of past application runs. The main challenge with this approach is the identification of the right set of input parameters that are needed to build a stable, scalable, and reliable model.
3.6 Tagging applications
While the previous approach requires a prediction model, this approach transfers the responsibility of setting the system configuration to the end user. The user is responsible for assigning a “tag value” to a given application. The system is designed to map these “tags” to a set of system configuration parameters. The challenge with this approach is that the reliability of the solution is completely dependant on the user’s ability to understand the application demands and choose the correct tag value.
4. Next steps for the sites
All the participating sites have reported that they plan to continue investing in research, development, and deployment of the solutions discussed above. The goal is to use the lessons learned and data collected to shape future procurement documents. Some sites have indicated their plans on extending the scope of system-level power-capping solutions to multiple systems that share the same facility. In addition, some sites have also expressed the need of accounting for power-draw by secondary infrastructure (e.g. cooling towers) that supports their HPC systems.
5. Solicitation of feedback and collaboration
The Energy Efficient HPC Working Group (EE HPC WG) would like to solicit feedback and participation from all members of the community including the government, academia, and vendors. For more details, please visit the working group’s website .
References:
[1] Whitepaper, “Energy and Power Aware Job Scheduling and Power Management”, Energy Efficient HPC Working Group, Working draft, https://eehpcwg.llnl.gov/documents/conference/sc17/sc17_bof_epa_jsrm_whitepaper_110917_rev_1.pdf
[2] Slides, ‘State of the Practice: Energy and Power Aware Job Scheduling and Resource Management’, Birds of a Feather Session, Supercomputing Conference 2017, https://eehpcwg.llnl.gov/documents/conference/sc17/sc17_bof_epa_jsrm.pdf
[3] Poster, “Global Survey of Energy and Power-Aware Job Scheduling and Resource Management in Supercomputing Centers”, Siddhartha Jana, Gregory A. Koenig, Matthias Maiterth, Kevin T. Pedretti, Andrea Borghesi, Andrea Bartolini, Bilel Hadri, Natalie J. Bates
http://sc17.supercomputing.org/presentation/?id=post236&sess=sess293
[4] The Energy Efficient HPC Working Group (EE HPC WG), https://eehpcwg.llnl.gov/
[5] Video summarizing the results of the survey, https://www.youtube.com/watch?v=jHpBYl-beI4
Sign up for our insideHPC Newsletter

