

Celestine Dünner from IBM Research in Zurich
In this video, researchers from IBM Research in Zurich describe how the new IBM Snap Machine Learning (Snap ML) software was able to achieve record performance running TesorFlow.
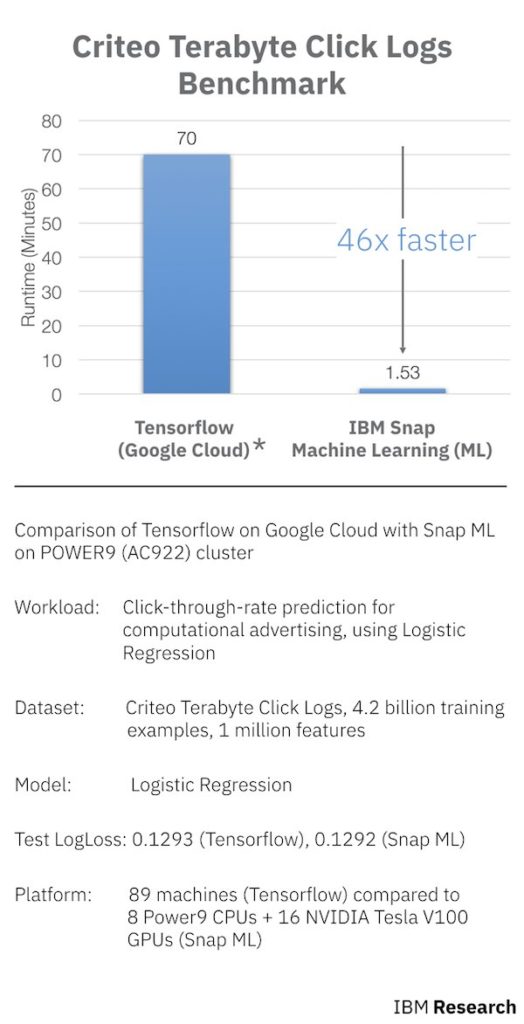
“In a newly published benchmark by IBM researchers, using an online advertising dataset released by Criteo Labs with over 4 billion training examples, we train a logistic regression classifier in 91.5 seconds. This training time is 46x faster than the best result that has been previously reported, which used TensorFlow on Google Cloud Platform to train the same model in 70 minutes.”
The AI software behind the speed-up is a new library developed over the past two years by our team at IBM Research in Zurich called IBM Snap Machine Learning (Snap ML) – because it trains models faster than you can snap your fingers.
The library provides high-speed training of popular machine learning models on modern CPU/GPU computing systems and can be used to train models to find new and interesting patterns, or to retrain existing models at wire-speed (as fast as the network can support) as new data becomes available. This means less compute costs for users, less energy, more agile development and a faster time to result.
The widespread adoption of machine learning and artificial intelligence has been, in part, driven by the ever-increasing availability of data. Large datasets enable training of more expressive models, thus leading to higher quality insights. However, when the size of such datasets grows to billions of training examples and/or features, the training of even relatively simple models becomes prohibitively time consuming. This long turn-around time (from data preparation to scoring) can be a severe hindrance to the research, development and deployment of large-scale machine learning models for critical applications such as weather forecasting and financial fraud detection.
Equally important, Snap ML is not only for large data applications where training time can become a bottleneck. For example, real-time or close-to-real-time applications, in which models must react rapidly to changing events, are another important scenario where training time is critical. For instance, consider an ongoing hack threatening the energy grid, when a new, previously unseen, phenomenon is currently evolving. In such situations, it may be beneficial to train, or incrementally re-train, the existing models with new data on the fly. One’s ability to respond to such events necessarily depends on the training time, which can become critical even when the data itself is relatively small.
![]()
A third area when fast training is highly desirable is the field of ensemble learning. It is well known that most data science competitions today are won by large ensembles of models. In order to design a winning ensemble, a data scientist typically spends a significant amount of time trying out different combinations of models and tuning the large number of hyper-parameters that arise. In such a scenario, the ability to train models orders of magnitude faster naturally results in a more agile development process. A library that provides such acceleration can give its user a valuable edge in the field of competitive data science or any applications where best-in-class accuracy is desired. One such application is click-through rate prediction in online advertising, where it has been estimated that even 0.1% better accuracy can lead to increased earning of the order of hundreds of millions of dollars.
The efficiency, results, and insights from machine learning have made it critical to businesses of all sizes. Whether a small to medium business is running in the cloud or a large-scale enterprise IT operation, which services many business units, machine learning puts pressure on compute resources. Since resources are typically billed in increments, time to solution will have a direct impact on the business’ bottom line.
Snap ML will be more broadly available later this year as a technology preview in IBM’s PowerAI machine and deep learning software distribution,” said Sumit Gupta from IBM. “We are currently looking for a few lead clients, who want to work with us to take advantage of Snap ML.”
 The three main features that distinguish Snap ML are:
The three main features that distinguish Snap ML are:
- Distributed training: We build our system as a data-parallel framework, enabling us to scale out and train on massive datasets that exceed the memory capacity of a single machine which is crucial for large-scale applications.
- GPU acceleration: We implement specialized solvers designed to leverage the massively parallel architecture of GPUs while respecting the data locality in GPU memory to avoid large data transfer overheads. To make this approach scalable we take advantage of recent developments in heterogeneous learning in order to enable GPU acceleration even if only a small fraction of the data can indeed be stored in the accelerator memory.
- Sparse data structures: Many machine learning datasets are sparse, therefore we employ some new optimizations for the algorithms used in our system when applied to sparse data structures.
This IBM Research breakthrough will be available for customers to try as part of the PowerAI Tech Preview portfolio later this year and in the meantime, we are actively looking for clients interested in pilot projects.

