

Scott Baden from LBNL leads the Pagoda Project for ECP.
In this episode of Let’s Talk Exascale, Scott Baden of LBNL describes the Pagoda Project, which seeks to develop a lightweight communication and global address space support for exascale applications.
What can you tell us about your project?
Scott Baden: DOE’s [the US Department of Energy’s] exascale computers will comprise thousands of individual processing nodes connected by high-speed communication networks, and performance of the communication among the nodes can be critical to meeting the ECP’s application performance goals. The Pagoda Project is developing communication software libraries with low operating overheads that will enable application and software developers to tap the high performance of DOE’s exascale computers.
Why is this area of research important to the overall efforts to build a capable exascale ecosystem?
Scott Baden: Exascale applications often use irregular representations, and these reduce computation and memory costs. These representations are difficult to manage—even on a single processor—but are much more challenging on the physically distributed memories of a supercomputer. The principal challenges arise out of moving data at small granularities or sizes. Because the cost of moving the data includes a fixed cost, when you’re sending small amounts of information, it is the fixed cost that accounts for most of the communication overhead. Fine-grained communication is often found in applications that use irregular representations. What our project is addressing is how to keep the fixed cost as small as possible, so that cutting-edge irregular algorithms can efficiently move many small pieces of data efficiently.
Now, another challenge is how to reduce the amount of data that must be moved. Generally speaking, we think about moving data to where the computation will take place. However, in some cases, it may be more efficient to move the code to the data instead.
The final challenge is to overlap communication with computation whereby an application performs computation unrelated to communication that is in progress. The key to making this strategy work is to support asynchronous execution, that is, to express communication in a way such that we don’t have to wait for it to complete, but rather we can keep the processor busy with some other so-called “useful work.”
Our approach to addressing these three challenges is to implement a PGAS programming model, where PGAS stands for Partitioned Global Address Space. Our PGAS model relies on one-sided communication as opposed to two-sided communication, which is employed with message passing.
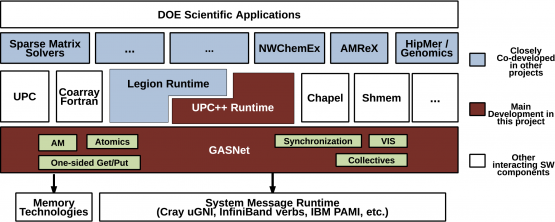
The software developed under the Pagoda project consists of two tightly coupled software libraries, one layered on top of the other. At the top level is UPC++, a C++ class library that is intended for application developers. We call it a productivity layer. At the bottom level is GASNet, a communication library that provides a backend to the vendor-provided, low-level communication facilities that operate the system interconnect.
GASNet provides a portable but efficient layer on top of the vendor communication libraries to accomplish this goal. It frees developers from the time-consuming and error-prone process of writing their own backend to handle communication. This is the part of their software that actually manages the interconnect itself.
 The UPC++ programmer can expect communication to run at close-to-hardware speeds because it takes advantage of GASNet’s low-overhead communication as well as access to any special hardware support such as RDMA [remote direct memory access]. For example, some vendors provide hardware support for collectives, and we can utilize that if it’s available. Industry is moving toward global addressability of distributed memory, and so GASNet embraces this model, enabling the PGAS applications to meet the performance goals by matching the communication model with what the hardware provides.
The UPC++ programmer can expect communication to run at close-to-hardware speeds because it takes advantage of GASNet’s low-overhead communication as well as access to any special hardware support such as RDMA [remote direct memory access]. For example, some vendors provide hardware support for collectives, and we can utilize that if it’s available. Industry is moving toward global addressability of distributed memory, and so GASNet embraces this model, enabling the PGAS applications to meet the performance goals by matching the communication model with what the hardware provides.
Now, UPC++’s design philosophy is to provide close-to-the-metal performance, and meeting this requirement imposes certain restrictions. In particular, non-blocking communication is the default for nearly all operations defined in the UPC++ API, and all communication is explicit. These two restrictions encourage the programmer to write code that is performant, and it also discourages the programmer from writing inefficient code, mainly by exposing operations that have a high cost. So the idea is that you want to encourage practices that lead to high performance.
Conversely, UPC++ relaxes some restrictions found in models such as MPI. In particular, it does not impose in-order delivery requirements between separate communication operations. The added flexibility increases the possibility of overlapping communication with computation and scheduling it appropriately to reduce the impact of communication overheads on the running time of the application.
In what ways is your research important to advancing scientific discovery, industrial research, and national security?
Scott Baden: Low-overhead communication is the holy grail of application scalability. That is to say, you double the size of the supercomputer, you double the performance, and so on. In fact, the “and so on” is what drives the ECP effort because the goal of ECP is to deliver supercomputers that are 50 times faster than what is available today. ECP applications need to see a corresponding capability enhancement of a factor of 50, so the benefit of exascale can advance DOE’s goals that you’ve mentioned. To this end, UPC++ and GASNet deliver near-hardware speeds for communication, which is an important determinant of performance. UPC++ addresses programmer productivity, enabling applications programmers to realize the low-overhead benefits of GASNet while shielding the programmer from the low-level details needed to realize high communication performance. So, by enabling application developers to have confidence that they can get high communication performance via higher-level programming abstractions, ECP developers can use cutting-edge algorithms to deliver large-scale capabilities, while keeping software development costs reasonable.
What are some of the most important technical milestones of your ECP research at this point?
Scott Baden: Well, there are a couple. One is to deliver a performant library that enables application developers to meet their performance goals. That’s the most important. The other is to ensure that we interoperate with message passing and asynchronous multitasking libraries. ECP applications that we work with tend to mix different types of execution models, so it’s important that the software tools developed in the ECP software stack coexist so that different parts of the software ecosystem can work together within a single application.
Updates to the GASNet libraries will provide network services appropriate for newer programming models that evolved since the original GASNet design. The earlier PGAS languages, which have been around for many years, include UPC and co-array FORTRAN. There are now new members of the community—UPC++, which we’re developing, as well as Legion and Chapel.
What collaboration and integration activities have you been involved in within the ECP, and what new working relationships have resulted?
Scott Baden: We’re working with four ECP projects currently: the AMREx co-design center at LBNL, which is developing software infrastructure for Berger-Oliger-Colella Structured Adaptive Mesh refinement; ExaBiome, an ECP application project involving metagenomics, also at LBNL; and two ECP software projects—the Sparse Solvers Project at LBNL and the Legion project at Los Alamos National Laboratory. We are also talking with the MPI developers to address the interoperability issue I mentioned earlier. As a result of meetings held at SC17 and the ECP Annual Meeting, new possibilities for collaborations have emerged, and we will report on them in the future.
How would you describe the importance of collaboration and integration activities to the overall success of the ECP?
Scott Baden: Any project in ECP must show relevance, not only to the overall mission of enabling high performance of ECP applications, but it must also coexist with other parts of the ECP software stack. As noted earlier, no application will be using just one paradigm or execution model.
Has your project taken advantage of any of the ECP’s allocation of computer time?
Scott Baden: Yes, we have. We’ve made modest usage to date, but we anticipate making greater usage for testing purposes—that is, scalabilty—in the coming decade.
What’s next for your ECP project?
Scott Baden: The project will deliver new enhancements to UPC++ and GASNet. UPC++ will add support for noncontiguous data transfers involving data that’s not laid out adjacently in memory, a common requirement of irregular applications mentioned earlier. In addition, we’ll add application-level, shared-memory bypass support, to reduce the cost of moving data when you know that the processes are living in the same physical address space. This capability takes advantage of processor support for in-memory data motion. We’ll also enhance the performance of atomics, which support indivisible updates to memory, useful in implementing lock-free synchronization. Last, we’ll add team-based collectives that will support communication within subsets of processors. Such support is required by certain algorithms of interest to ECP, such as graph algorithms.
For GASNet, the next steps are lower-level support for noncontiguous data transfers and the atomics, mentioned earlier, for UPC++. In addition, some specialized performance tuning will be undertaken to better utilize the Cray Aries interconnection network.
Is there anything else you would like to add?
Scott Baden: It’s been an interesting and exciting project. I look forward to continued developments with the Pagoda project, and I feel privileged to be working with such a talented group that comprises the Pagoda team.
