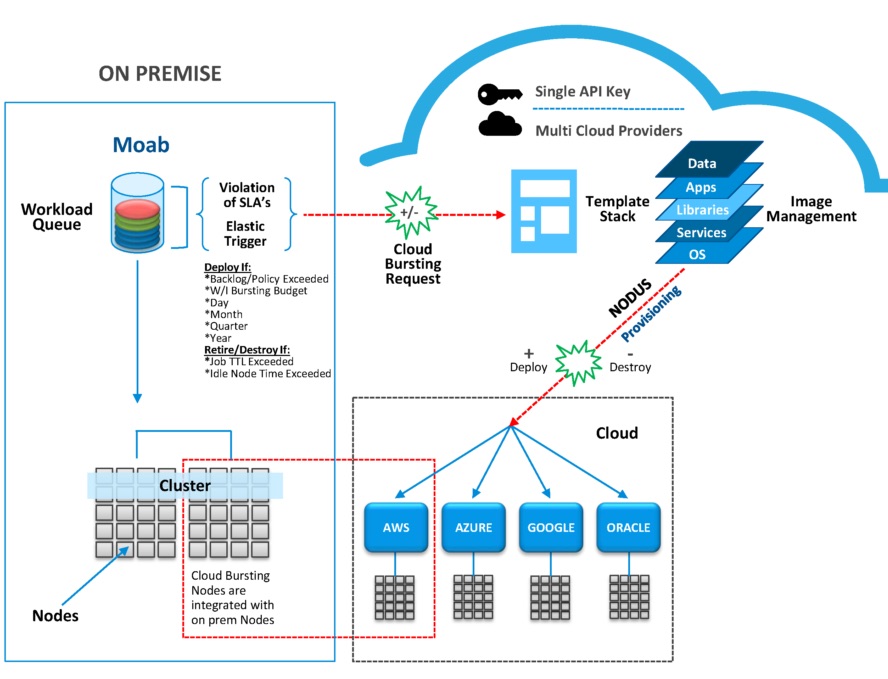
Adaptive Computing is getting increased traction with their new NODUS Cloud Bursting Solution.
Typically, each HPC organization does a partial or complete cluster refresh every three to five years. Due to the maturity of cloud hardware and software providers, when organizations refresh their HPC cluster they need to consider cloud bursting as part of their overall strategy.
HPC organizations that utilize cloud service providers (AWS, Azure, Google, Oracle, etc.) in conjunction with Adaptive Computing’s NODUS Cloud Bursting Solution can significantly reduce their on-premise cluster sizes and costs by as much as 40-50 percent, and burst the rest of their HPC workload to the cloud, by implementing this hybrid approach.
Each workload that is run in the cloud can be matched with the exact hardware stack that is best suited for that workload. This approach will assure all workloads are completed in the timeliest and most cost-efficient manner, typically saving millions of dollars on “on-premise” HPC cluster capital expense. These savings can be moved to a manageable cloud-bursting op-ex cost (pay-as-you-go).
With the reduction of on-premise HPC cluster sizes, additional savings are achieved by reducing power consumption, cooling costs and support personnel.
Adaptive Computing’s new NODUS Cloud Bursting Solution was released in January 2018, and additional features are planned for the next six months.
Since launching the NODUS HPC Cloud Bursting Solution, the company has given over 35 demos, with several organizations moving into the proof-of-concept (POC) phase, an indication that HPC users are embracing the idea of leveraging public clouds to ensure their work can get done,” according to Arthur Allen, president of Adaptive Computing.

