Sponsored Post
 Optimizing data compression methods has become more critical than ever for cloud storage, data management, and streaming applications. Working with compressed data reduces network bandwidth, data transfer times, and storage costs. But high levels of compression and decompression take a toll on compute resources that can degrade overall system performance. Which is why the Intel® Integrated Performance Primitives (Intel IPP) data compression libraries play a crucial role by providing highly optimized, plug-and-play implementations of all the common data compression algorithms.
Optimizing data compression methods has become more critical than ever for cloud storage, data management, and streaming applications. Working with compressed data reduces network bandwidth, data transfer times, and storage costs. But high levels of compression and decompression take a toll on compute resources that can degrade overall system performance. Which is why the Intel® Integrated Performance Primitives (Intel IPP) data compression libraries play a crucial role by providing highly optimized, plug-and-play implementations of all the common data compression algorithms.
There are important trade-offs between the degree of compression and the computational resources required to compress and decompress data. Choosing the right method and implementation gives the greatest benefit, as does designing the right algorithms to ensure the proper alignment of data and sizing the data to fit in the CPU cache. Algorithms that employ the latest CPU architectures, SIMD extensions, and bit manipulation instructions will further improve performance.
A challenge for optimization on modern platforms comes from the strong data dependency inherent in most algorithms. This can limit the use of single instruction/multiple data (SIMD) instructions to mostly pattern searching. Still, the improvements in the data compression functions implemented in Intel IPP are designed around algorithmic and data layout optimization, and the latest CPU architectures.
By selecting proper starting conditions for input data processing, for example, can give immediate performance gains. Searching for patterns in input data using a minimum match length of two to three bytes will detect more matches and obtain a high compression ratio. But this drastically increases input data processing time. Choosing the best minimum match length needs to balance compression ratio to compression performance. Using statistical experiments and implementing condition checks and branches early in the code to detect the most probable situations greatly improves overall efficiency.
Also, ensuring proper data alignment saves CPU cycles on data reads and writes because most CPUs execute faster on aligned data than on nonaligned data, especially with data elements longer than 16 bits.
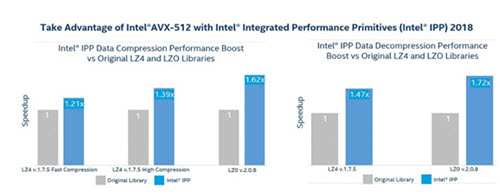
Each Intel IPP function employs multiple code paths optimized for specific generations of Intel and compatible processors, including Intel Atom™, Intel Core™ and Intel Xeon®. Each release adds new optimized code, so developers can just link to the newest version of Intel IPP to take advantage of the latest processor architectures.
As a result, Intel® Integrated Performance Primitives (Intel IPP) offers the developer a highly optimized, production-ready, library for lossless data compression/decompression that targets image, signal, and data processing, and cryptography applications.[clickToTweet tweet=”Data compression is critical for cloud and streaming applications. Download the Intel IPP library for free. ” quote=”Data compression is critical for cloud and streaming applications. Download the optimized Intel IPP library of compression primitives for free. “]
The Intel IPP optimized implementations of the common data compression algorithms are “drop-in” replacements for the original compression code. But there is always a tradeoff. There is no “best” compression algorithm for all applications. For example, BZIP2 achieves good compression efficiencies but because it is more complex, it requires significantly more CPU time for both compression and decompression.
Intel® IPP 2019 Beta introduced some new functions to support the ZFP floating-point data compression and decompression. ZFP is a lossy floating point data compression with controlled compression accuracy and compression rate. Intel® IPP ZFP functions are highly optimized for Intel® AVX2 and Intel® AVX-512 instruction sets, which is significantly faster than the open-source implementation.
On the other hand, LZ4 compression is about 20x faster than BZIP2 on the standard compression data, while BZIP2 achieves the best compression ratios. ZLIB provides a balance between performance and efficiency, which is why this algorithm is chosen by many file archivers, compressed network protocols, file systems, and lossless image formats. Compared with the open-source ZLIB code, the Intel IPP ZLIB implementation can achieve a significant performance improvement at different compression levels while providing fully compatible APIs and compression results.
Altogether, Intel IPP includes more than 2,500 image processing, 1,300 signal processing, 500 computer vision, and 300 cryptography and compression optimized functions for creating digital media, enterprise data, embedded, communications, and scientific, technical, and security applications.
Intel IPP 2018 is supported on various Microsoft* Windows*, Linux* operating systems, as well as MacOS*, and Android* OS, and is available as part of Intel Parallel Studio XE and Intel System Studio tool suites, as a free stand-alone version and is also available for download through YUM and APT repositories.

