This is the final post in a five-part series that explores the potential machine and a variety of computational approaches, including CPU, GPU and FGPA technologies. This post explores unified deep learning configurations and emerging applications.

Download the full report.
Previous sections have described the complementary strengths of CPUs, GPUs, and FPGAs for different types of deep learning operations. With the emergence of new use cases, there will be a growing benefit of unified deep learning configurations combining all three types of hardware elements into single hardware nodes. This is illustrated with a few specific examples.
Training and inference are typically thought of as very distinct operations today, but there are emerging applications that will combine them. Continuous and reinforcement training can be used when a deep learning system is deployed in an environment where regular retraining and updating of a DNN is required. For example, systems that control devices in real time can be continuously learning and adapting based on the results of their previous actions. Similarly, systems that interact with humans can use feedback from humans to continuously improve their training. A unified deep learning platform that simultaneously employs GPUs for training updates and FPGAs for inference enables efficient implementation of such continuous training systems.
Simulations can also be used for training. There are many scenarios in the field of autonomous driving, surveillance, and other areas where large amounts of training data may not be available. Creating large datasets with labeled images or scene-specific pedestrian detectors is extremely costly. This also applies to designing deep learning based controllers for lane merging, and other situations. To circumvent this problem, modern computer games are being used to provide training data by simulating real life situations. A unified system with very robust hardware capabilities is needed for such combined simulation / deep learning systems.
Many systems can have serious negative consequences for certain types of wrong predictions.
Many systems can have serious negative consequences for certain types of wrong predictions. One example is an autonomous vehicle that fails to correctly identify the presence of a stop sign. There are cases where such failures occur when stop signs are slightly modified, such as when a small sticker is placed on them. One approach to reducing such errors is to combine multiple types of analysis: multiple DNNs independently trained with different data, plus the use of a digital map of all known stop signs in the area, plus an expert system that predicts circumstances where a stop sign is likely to be present. A supervising routine would evaluate the input from all these sources to make a more reliable determination about the presence of a stop sign. This type of hierarchy of heterogeneous machine intelligent systems mimics how many human decisions are made, and is expected to become more common over time.
Another active area for developing machine intelligence applications combines deep learning and data analytics on very large-scale datasets or real-time data streams.
These types of systems combining DNNs with other operations require the variety of rapid compute capabilities that a combination of CPU, GPU, and FPGA functions provides.
A heterogeneous configuration of components within a node can also optimize functions other than machine intelligence, as shown in the example in the figure below. The FPGA in this configuration is used to implement a highly optimized intelligent interconnect between the server blades. It is easy to envision adding GPUs to such a blade, with possible additional support in the FPGA for machine intelligence related communication and collective functions, resulting in a highly optimized heterogeneous server for large datacenter machine intelligence operations.
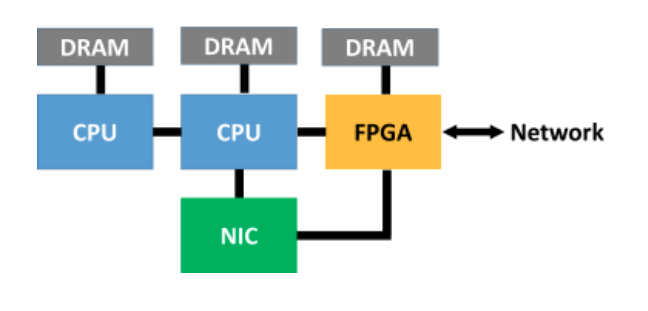
FPGA Exploitation
The CPU, GPU, and FPGA coupling provides for a software selection of a la carte solutions that can be optimized in a wide variety of ways that are hidden from the user. A unified software stack is not only elegant but provides for a maximum efficiency management of system resources. This also applies to subsequent hardening of FPGA configurations in ASICS or other forms of efficient hardware embedded IP. It is also worth repeating that higher-level frameworks (e.g., TensorFlow, Theano) can effectively hide the heterogeneity from application developers as well as facilitate portability across different systems. This is a powerful enabler for heterogeneous hardware.
Summary
It is clear the use of deep learning applications is expanding. The combination of very large data sets, robust algorithms, and high-performance compute platforms enables a large variety of applications for commercial deployment. The compute requirements are substantial and growing for both training and inference. As a result, unified deep learning configurations combining CPU, GPU, and FPGA products are emerging as powerful solutions that enable the compute capabilities and flexibility that are needed to address these challenges.
Moreover, with a rich collection of optimization libraries that target all three compute elements, a heterogeneous system can be optimized with a hybrid of resources and application requirements that can adapt at run time. The ROCm software stack and MIOpen are excellent building blocks for this. They also support a growing community of open architecture application development that includes these different compute solutions.
[clickToTweet tweet=”It is clear the use of deep learning applications is expanding. #deeplearning” quote=”It is clear the use of deep learning applications is expanding. #deeplearning”]
Xilinx provides Reconfigurable Acceleration Stack, which consists of the pre-built hardware platform on FPGA, a runtime and design tools to enable development of a broad set of customized deep learning solutions. xfDNN middleware from Xilinx captures the software features essential for implementing deep learning inference on FPGAs.
We know that the solution landscape is evolving rapidly, and that flexibility is the key for maintaining relevance. A unified CPU, GPU, and FPGA solution provides a hedge against algorithm obsolescence and assures the best framework for future proofing.
The combination of high performance CPUs, GPUs, and FPGAs with heterogeneous support in the software stack results in a total system package that is greater than the sum of its parts. It is a solution in which emerging deep learning applications and system designs can be balanced in terms of flexibility and performance.
Over the past few weeks, this series also covered the following topics:
- The Machine Learning Potential of Combining HPC Technologies
- Exploring the Potential of Deep Learning Software
- The Ins and Outs of DNN Implementation and Optimization
- Computational Approaches for Deep Learning – CPU, GPU, and FPGA
You can download the full report here, courtesy of AMD and Xilinx, “Unified Deep Learning with CPU, GPU and FPGA technology.”


Totally agree. The scope of deep learning applications is expanding. What makes it all the more better is the fact that so many new startups are coming up and delivering practically viable results. The fact that these startups are constantly innovating makes AI based learning even more exciting.